2024年2月,中国存储行业迎来密集创新潮,十余家存储厂商接连推出DeepSeek大模型一体机。这场围绕“AI基础设施”的技术竞速,本质是存储企业从数据管理向全栈AI服务的能力跃迁,看的是你能为企业用户提供什么更好的服务。
新华三
2月10日,新华三集团对外发布基于DeepSeek大模型的一体机UniCube,全面搭载DeepSeek V3、R1模型,并实现671B DeepSeek大模型单机推理及单机训推一体服务。除了支持开箱即用1天内快速部署,这款一体机还内置了H3C AlStore智能资产平台,提供超过1000款开源数据集和模型资源,当企业需要“食材”(数据集)和“菜谱”(大模型)的时候能够就地取材。
UniCube针对金融、医疗、制造等垂直行业还提供深度定制的模型和应用,对行业所需的AI应用有定制化策略。还能提供从前期咨询、中期部署到后期运维的全生命周期服务。

H3C UniCube DeepSeek大模型一体机
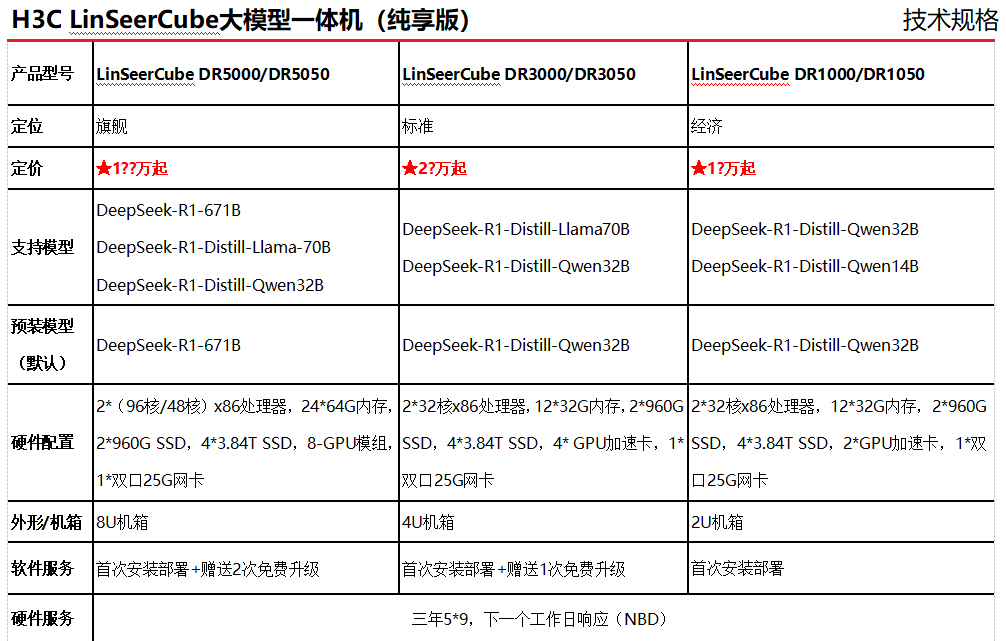
产品规格与型号
中科曙光
2月14日,曙光云推出的全国产DeepSeek大模型超融合一体机,主要应用场景为政务云、企业数据中心还有多行业适配。产品亮点第一个我们就能关注到的——全国产化。这款一体机采用了国产X86 CPU和国产GPGPU加速卡,支持全精度和半精度混合训练与推理,这样能有更高的计算性价比。
另外一体机全面适配DeepSeek系列模型(如V3、R1、Janus Pro),并支持全系列量化蒸馏版本,同时兼容QWen2.5、LLama3.2、ChatGLM等主流大模型。而且内置文心雕龙智能化应用,通过快速问答和知识库管理,帮助企业高效处理信息,提升运营效率。

宁畅
2月14日,宁畅发布DeepSeek大模型一体机解决方案。DeepSeek 大模型一体机解决方案从底层技术到业务场景深度优化。除了易部署,这些不同版本还集成了多款行业知识库与模板,并且通过内置资源监控与自优化算法,算力利用率可提升至85%,大幅降低总拥有成本,帮助企业实现高效、低成本的运维管理。

DeepSeek 大模型一体机解决方案产品矩阵
华为
2月13日,华为对外推出昇腾DeepSeek一体机,深度融合昇腾高性能算力底座与DeepSeek全系列大模型能力,覆盖语言理解、图像分析、知识推理等全场景需求。以DeepSeek-R1-Distill-Llama-70B为例,其系统每秒吞吐量可达3300 Tokens,轻松应对海量文本分析和复杂业务场景模拟。
一体机还支持低至50ms的每用户时延,就是哪怕很多人同时用,系统对每个用户的时延也控制在50ms以内(简单来说就是打游戏不卡的程度),可以提升个人办公效率。以DeepSeek V3/R1满血版为例,能支持高达192个用户的并发,满足大型企业多部门协同工作的需求。
一体机采用华为Atlas800l A2推理服务器,搭载鲲鹏920+昇腾AI处理器,支持全精度和半精度混合训练与推理。混合推理跟曙光提到的点相同,就是回答你的问题,简单的要求能快速批量处理(半精度),复杂的精密任务就会更注重细节(全精度)。
截止2月12日,已有13家伙伴基于昇腾产品打造自有DeepSeek一体机产品。

宏杉科技
2月13日,宏杉科技对外推出基于DeepSeek的大模型一体机解决方案。宏杉科技DeepSeek一体机解决方案除了易部署,还提到了灵活扩展性,能满足私有化部署对海量数据存储的需求。同时,内置多种数据保护模式,并可根据数据访问级别配置性价比更高的存储介质。
宏杉科技还内置了自研功能组件,可无缝对接各类型生产系统,实现数据自由流转。同时,搭载智能AI文档库产品,支持知识协作共享和跨领域多模态检索,提升企业数据管理效率。

联想集团
2月初,联想集团与国产GPU企业沐曦股份联合发布了基于DeepSeek大模型的首个国产一体机解决方案。方案以“联想服务器/工作站+沐曦训推一体国产GPU+自主算法”为核心架构,配合联想AI Force智能体开发平台,推出智能体一体机与训推一体服务器双产品形态。
联想创新性推出两大产品:面向敏捷部署的DeepSeek智能体一体机采用ThinkStation PX工作站为载体,搭载沐曦曦思N260国产GPU。实测数据显示,在相同并发条件下,沐曦曦思N260国产GPU在Qwen2.5-14B模型推理实测性能达到NVIDIA L20 GPU的110%-130%,可支持本地部署DeepSeek各种参数蒸馏模型推理。而面向更广泛场景的DeepSeek训推一体机则基于联想问天WA5480 G3 AI服务器,搭载8张曦云C500国产GPU,可为大模型训练和推理提供强大的算力支撑。

基于联想ThinkStation PX的智能体一体机

基于联想问天WA5480 G3 AI服务器的训推一体机
浪潮
2月7日,浪潮云联合沐曦股份、铨兴科技等生态伙伴,对外发布了预置DeepSeek-R1和DeepSeek-V3模型的海若一体机,实现671B DeepSeek大模型国产GPU单机推理服务。同样是开箱即用,部署时间1-3天。大模型推理性能有大幅提升,解码生成速度提升185.7%,平均首字时延降低55.9%。
开放兼容性高,支持浪潮海若、DeepSeek、GPT-4、通义千问等主流大模型;支持EmBedding、ReRanker、ASR、TTS多类型;内置模型池适配沐曦、昇腾等多种芯片。规格也有版本之分,有启航版、进阶版、旗舰版等多种规格,可根据模型参数和应用规模灵活选择。

海若一体机产品能力全景图
铨兴科技
2月18日,铨兴科技对外发布DeepSeek R1 671B 超显存融合训推一体机系列。包括三个版本:
671B 推理一体机入门版:价格 9.8W 起,支持 DeepSeek R1 671B 模型部署,强调极致性价比,输出最高可达 12TPS。
671B 推理一体机满血版:被称为 “性能机皇”,支持 DeepSeek R1 671B 满血版模型部署,超显存融合赋能高效推理,配置为 RTX5880 ada 48GB x10、Intel 4410Y x 2、512GB DRAM。
671B 满血版训推一体机:成本再降 95%,助力国产模型训练,支持 DeepSeek R1 671B 满血版本地训练,采用双节点配置,每节点含 RTX5880 ada 48GB x 8、Intel 4410Y x 2、2TB DRAM、400Gb 网卡、AI Cache Pro 2TB x 4 。

超聚变
2月17日,超聚变对外发布deepseek大型一体机。其优势在于开箱即用,分钟级交付。拥有一站式工具链,兼容主流模型,提供专业服务;多元算力融合,AI 资源可视可管,算力共享等。

产品规格包括:
轻量版:适用于低成本、低时延推理,如文本生成、简单问答,支持 1.5B – 14B 模型。
标准版:平衡成本与性能,适用于代码辅助、学术研究等,支持 32B – 70B 模型。
旗舰版:面向高性能推理,如尖端科研、商业决策,支持 671B 满血模型。
紫光云

紫光云公司推出的是紫鸾大模型一体机,已经全系优化适配并预制DeepSeek R1系列推理模型,支持英伟达、天数、昆仑芯、燧原科技等异构芯片的统一调度。通过一体化开箱即用私域部署,紫鸾大模型实现了DeepSeek的部署,为政企用户提供高性价比的生产级AI解决方案。
京东云

2月8日,京东云对外发布DeepSeek大模型一体机,基于“本地化开箱即用”的理念,提供从底层算力、模型服务、推理能力、应用开发的全栈解决方案,支持华为昇腾、海光、寒武纪、摩尔线程、天数智芯等国产AI加速芯片,在满足自主可控的同时,降低算力投资成本,主要面向金融、政府及企业用户。
昆仑技术+中科加禾
2月18日,昆仑技术与中科加禾携手推出的DeepSeek本地化部署一体机,产品基于昆仑技术的KunLun AI服务器算力和中科加禾的SigInfer模型推理引擎,提供稳定可靠的生产级DeepSeek-R1和V3服务。这个要简单说两句,河南昆仑技术有限公司成立于2022年10月,核心团队来自鲲鹏与昇腾的原班人马,是一家专注于算力基础设施与服务的高科技企业。中科加禾的 SigInfer 模型推理引擎可以理解为是一个非常聪明的 “大脑助手”。它主要做的事情就是帮助各种人工智能模型快速、准确地 “理解” 和处理数据,然后给出相应的结果或判断。这个是昨天才发布的,但是两家公司一个背靠华为一个背靠中科院,产品应该不会差,这里先备注一下。
产品优势生态兼容:全面兼容昇腾生态,满足本地化部署需求。
灵活配置:2节点起配,支持64并发,可按需线性扩容。
性能定制:高性能推理引擎,支持灵活定制以实现领先推理性能。
开发加速:集成 AI Space 开发平台,加速 AI 场景化持续创新。
技术支持:超100人的 FAE 团队提供安装部署及调优技术支持。