
大家都在谈论AI,纷纷接入DeepSeek一体机,这表明了拥抱生成式AI迫切的心情,在这个时代,有人说,千卡、网卡,万亿参数之外,负载均衡非常重要,对此你相信吗?
似乎有跟风炒作的嫌疑!
但有没有想过,企业拥抱AI大模型与个人接入最大不同是什么?
最大的不同其实是数据!
企业拥有很多专属的数据,这些数据有数据库管理的结构数据,也有大量的文本、图片、视频等非结构化数据,如产品技术资料、白皮书文档,以及热线用户反馈的各种数据,这些宝贵的数据与DeepSeek大模型的结合,才是企业拥抱AI大模型的关键。
不结合企业私域数据的DeekSeek一体机接入,不是真正的AI大模型应用!
结合企业私域数据的AI大模型应用有很多思路,如模型微调(Fine-tune)、检索增强生成(RAG)等,需要用到向量数据库、多模态融合、知识图谱构建等诸多的技术。所针对的应用场景,也并非单一的对话和代码、影像生成,结合企业的私域数据,对于生产过程,销售行为进行预测和指导,甚至是声明式的数据创新应用,这些都是AI大模型赋能企业创新应用的价值所在。
需要意识到,企业级未来应用主体的变化。此前,业务应用需要各种SaaS服务来赋能,业务需要依靠各种App来提供支撑,App提供的功能可以用来进行业务创新,App没有的功能,就需要进行开发、等待;但是大模型会改变这种应用的方式,未来应用将围绕着大模型,业务人员采用自然语言,用声明式的方式提出需求,用于各种目的的业务支撑。例如:销售线索的挖掘,销售可以以一个典型用户为范本,要求大模型推荐类似性质的用户数据,要求大模型赋能。
AI大模型可以满足类似的需求吗?
问题的关键不在AI大模型自身,关键在于AI大模型与私域数据的结合,换句话说,企业需要针对AI大模型准备好的数据,所谓Data for AI,这里就涉及到数据向量化、知识图谱构建等过程。如果没有这些数据,巧媳妇也难为无米之炊,这不是难为AI大模型吗?
如果说数据是基础,那么,性能就是保障。千卡、万卡也好,RAG也罢,相应能力至关重要,也是一个基本的前提。
为了实现可用性,堆积GPU算力很关键,但是发挥这些算力的能力,物尽其用也非常重要。私域数据如何在不同的节点之间高效调度,同一节点,不用GPU卡之间的数据调度,就非常重要了!
不同节点之间的数据调度需要依靠负载均衡,同一节点内部GPU之间需要依靠NCCL(NVIDIA Communication Library),这都是实施的关键细节。
对于负载均衡需要多说一句,现在已经升级为ADC(Application Delivery Controller,应用交付),从访问流量的负载均衡上升到App或者称为微服务的安全、交付和管理。据专业人士介绍:在如今火热的DeepSeek在训练和推理场景中,专业的AD平台可以助力大量数据的路由和海量训练数据快速、安全的加载,这也是刚刚结案的一个印度客户案例的应用实践。
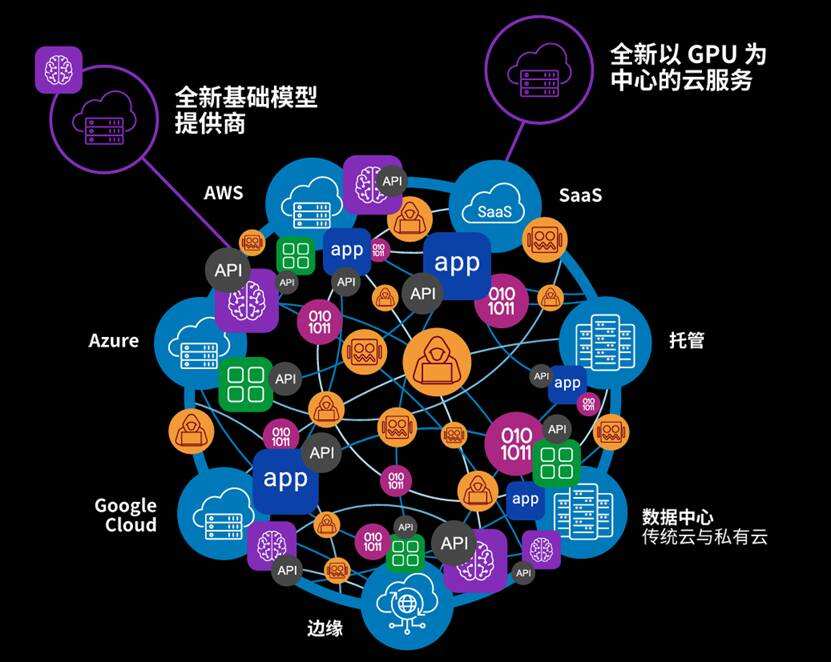
专业的ADC平台的高吞吐量、安全性和本地部署的能力,能够帮助客户进一步降低了整个DeepSeek训练和推理应用的成本。在AI的其他应用场景,包括RAG场景,ADC都可以发挥重要的作用。
对此,还真不容易想到!对吗?







