凭借多项优化技术,DeepSeek把大模型的训练和推理成本做到了不可思议的程度。而在2025年的GTC上,英伟达亲自下场优化大语言模型的推理性能,直接把DeepSeek的推理性能提高了30倍。
如果说,DeepSeek技术开源周让很多提供DeepSeek大模型服务的企业感受到了技术上的差距。那么,英伟达这次出手似乎是在抹平技术差距,因为英伟达直接把这项推理优化软件给开源了,不只是优化DeepSeek,也能优化LLama等模型。

DeepSeek能以极低成本提供在线服务,而英伟达开源的NVIDIA Dynamo也要类似的效果。英伟达创始人黄仁勋也表示,Dynamo可以帮AI工厂实现降本增效。他所说的AI工厂,一般指提供“智能”产品的数据中心,也可以指提供AI服务的服务商(MaaS)。
英伟达的Dynamo让AI推理服务成了一门不错的业务
DeepSeek开源周之后,有提供DeepSeek在线服务提供商宣布停止提供DeepSeek服务。而在我看来,Dynamo是可以让提供AI服务这件事,成为一门更好的业务。所以,Dynamo是一个值得所有AI专家都会关注的软件。

黄仁勋在主题演讲中再次提到了扩展定律的三条实现路径。第一种是预训练,基于海量数据从无到有训练出几千亿权重参数的模型。第二种是后训练,包括微调、蒸馏之类的。第三种就是以长思考为代表的模式,指的就是DeepSeek-R1这类推理模型。
很显然,推理模型将成为主流。OpenAI已经表示,已经发布的GPT 4.5将是最后一代非推理模型,以后传统大语言模型会越来越少。DeepSeek-R1能引起轰动,很大程度上也是因为它是一个推理模型,其智能水平有目共睹。
推理模型通过长思考提高智能水平,过程中会产生大量的Token。英伟达加速计算总经理兼副总裁Ian Buck表示,推理型AI带来了百倍以上的Token市场机会,也将为数据中心市场带来万亿美元规模的市场机遇。
当然,考虑到推理模型的计算成本在显著提高,如何降低推理成本就显得尤为重要。为了此,英伟达才推出了Dynamo。Dynamo整体降低推理成本,而成本降低则会让AI应用进一步普及,普及则带来巨大的市场增长。
Ian Buck表示,Dynamo可以让服务提供商在“用户交互体验”和“整体tokens产量”之间灵活调整,获得最好的业务回报。在我看来,这给了AI服务提供商更大的灵活性,也可以提供增加收入机会,让AI服务成为一个更好的生意。
稍微解释一下。
用户交互体验好跟不好,一般指的就是模型响应的速度。如果AI模型能迅速响应并输出结果,这种服务的响应速度快,用户体验非常好,而企业可以为这种高实时性的服务设定一个更高的价格,或者作为会员专享服务。
如果比较在意成本或者性价比,则可以考虑一次性处理大量请求。这样一来,虽然每个请求的响应速度会慢一些,但整体上能提高AI工厂的输出效率,在有限的资源下提高整体业务产出的量。
英伟达的Dynamo是什么?是怎么做到的?

与深度求索面向DeepSeek模型的优化不同,英伟达的Dynamo通用性显然更强,它面向英伟达的Hopper和Blackwell显卡优化,它可以支持PyTorch框架,以及SGLang、NVIDIA TensorRT-LLM和vLLM这三个推理引擎。
所谓推理引擎,说白了就是运行大语言模型的工具,本地个人电脑上常用的是Ollama,企业大规模分布式部署则要使用SGLang、NVIDIA TensorRT-LLM和vLLM这些专用的推理引擎,这些可以更好地支持分布式推理和高并发。
我简单学习了一下Dynamo的创新之处,发现它跟DeepSeek的优化技术有很多“英雄所见略同”的感觉,以下是Dynamo的5大创新点:
1,Dynamo可以支持更灵活的资源配置。
Dynamo可以高效地编排和协调大量给到GPU的AI推理请求,协调并加速数千个 GPU之间的推理通信。它通过一个叫GPU 规划器 (GPU Planner)的东西,能动态地添加和移除GPU,以适应不断变化的需求,从而避免GPU配置过度或不足。
这让我想起了DeepSeek介绍的类似操作,DeepSeek在业务高峰期时会配置更多GPU进行推理。而在业务低峰期,比如在晚上,会把一部分GPU拿来做研发或者训练,如果不训练至少也能省一些电费。这应该也是Dynamo所追求的效果。
2,Dynamo把处理阶段和生成阶段解耦,性能和灵活性都大大提高。
传统做法中,由于处理阶段(Prefill,预填充阶段)和生成阶段(Decode,输出Token阶段)的不平衡,会导致GPU有更多空闲时间。处理阶段是计算密集型的,而生成阶段是延迟敏感型的。如果能把两者解耦,不仅能提高利用率,还能提高整体吞吐。

Dynamo将大模型的处理阶段和生成阶段进行了解耦。这首先带来了性能的提升,上图显示,单节点性能提升30%,双节点提升100%。如果GPU数量越多,分布式并行处理的优势越明显,效率提升越高。
而且,将处理阶段和生成阶段解耦之后,Dynamo提供了更高的灵活性。它支持灵活设置首次令牌时间 (TTFT) 和令牌间延迟 (ITL)。AI技术服务商可以优先考虑更快的TTFT、更低的 ITL,或者更高的吞吐量,通过类似会员专享的服务获得额外收入。
3,Dynamo支持智能路由技术,可减少重复计算,提升性能。
模型推理过程中,我们发给模型的文字(或者图片)都会生成KV Cache,如果后续发给模型的内容跟之前有重合,那就可以利用缓存的结果直接输出,这样就不用重新计算了,输出速度也更快。

针对这个特性,Dynamo提供了一种更智能的路由方法。它不是根据负载繁忙程度来选节点,而是根据缓存数据的情况来进行路由,智能选择缓存了最适合处理当前请求的节点。最终让TTFT,平均请求延迟,以及整体吞吐量都得到了优化。
4,Dynamo支持把KV Cache卸载到CPU、SSD甚至是对象存储上。
刚才说了KV Cache是干啥的了,默认情况下它是存放在显存里的,如果进行多轮对话就会占用更多显存。然而,众所周知,显存是非常稀缺的资源,很多人为了大容量显存就得买价格高很多的高端显卡,高端显卡的成本自然也很高。
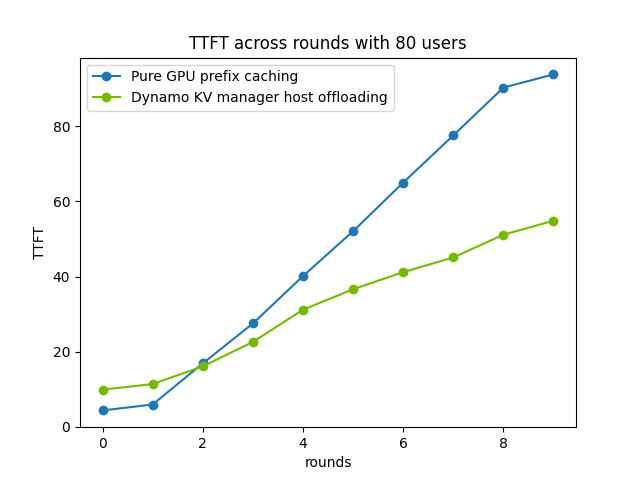
Dynamo提供了一个叫显存管理器 (Memory Manager)的东西,目前已经支持把KV Cache卸载到CPU用的DRAM内存上,下一步还打算把KV Cache放到SSD上,未来甚至还打算支持放到通过网络访问的对象存储上,简直了。
把KV Cache从显存中搬到DRAM之后,GPU显存得到释放,GPU处理新请求的效率也直线上升,“首个token响应时间”(TTFT)也大大缩短,用户体验显著改善。
5,支持数据跨介质高效传输的低延迟通信库——NIXL
NIXL是一种数据传输工具,可以优化数据在AI推理系统内部不同存储介质之间的传输过程。传统的数据传输库只支持一种介质,而NIXL具备跨多种存储介质传输数据的能力。
介绍中提到,NIXL能高效地在不同内存设备和快速存储设备间并完成数据传输,可能是指在GPU显存、CPU内存或者SSD之间,是用来优化KV Cache传输的,也是一个能提高性能的工具。
Dynamo已经引起了广泛关注
在这么多创新技术的联合之下,效果也确实非常诱人。在GPU数量相同的情况下,Dynamo可将 NVIDIA Hopper平台上运行 Llama 模型的 AI工厂性能和收益翻倍。
在由GB200 NVL72机架组成的大型集群上运行 DeepSeek-R1时,Dynamo的智能推理优化也可将每个GPU生成的 Token数量提高30倍以上。看来对新显卡架构的优化加成更大。
英伟达提到,包括亚马逊云科技、Cohere、CoreWeave、戴尔科技、Fireworks、谷歌云、Lambda、Meta、微软 Azure、Nebius、NetApp、OCI、Perplexity、Together AI 和 VAST,都将受益于Dynamo。
Perplexity AI 首席技术官 Denis Yarats 表示:“我们期待通过 NVIDIA Dynamo 及其增强的分布式服务能力,进一步提高推理服务效率,满足全新 AI 推理模型的计算需求。”
Cohere 工程部门高级副总裁 Saurabh Baji 表示:“我们期待 NVIDIA Dynamo 能帮助我们为企业客户提供卓越的用户体验。”
Together AI 首席技术官 Ce Zhang 表示:“NVIDIA Dynamo 的开放性和模块化使我们能够将其组件无缝嵌入引擎,以满足更多请求,同时优化资源利用率,从而最大化我们在加速计算方面的投资。我们很高兴能够利用该平台的突破性功能,经济高效地为用户提供开源推理模型。”
NVIDIA Dynamo将作为 NVIDIA NIM 微服务推出,并在未来版本中由 NVIDIA AI Enterprise 软件平台提供支持。想要高效推理模型的专家应该都不会错过Dynamo吧。