3月27日,2025人工智能基础设施峰会期间,数据智能技术应用论坛上,铨兴科技副总经理、产品研发中心负责人邱创隆发表了技术演讲《AI发展推动下的数据存储升级》,深入分析AI技术演进对存储系统带来的多维挑战,并分享了铨兴科技在企业级存储与AI训练推理场景下的最新产品与实践应用。

AI大模型加速演进,带动“存力”重构
AI发展的本质推动不仅是“算力升级”,更是“数据流重构”。从ChatGPT-1到GPT-4,其模型参数量和训练数据体量增长了8倍,未来面向ChatGPT-X代模型,这一数字甚至可能有50倍的增长。支撑大模型成长的,是指数级膨胀的数据量和日趋严苛的数据处理效率要求。
与此同时,大模型从应用角度还面临算力的三大痛点:
算力需求大:例如从GPT-3到Llama-3,从开始使用3640 PD(每天完成的的千万亿次浮点运算量petaflop/day)到421875 PD,计算量增长约116倍;
计算效率低:高昂的GPU资源往往无法充分利用,带来极大浪费;
能耗压力大:以训练10万亿参数模型为例,需用10万张H100、运行1193天,耗电40亿千瓦时,相当于1.4亿美国家庭一天的用电量。
内存方面,在AI模型高度运算趋势下,训练过程对内存的依赖性也日益增加。据SK海力士数据显示,BERT时期仅5%的计算为内存密集型任务,而到GPT-3已高达92%。内存虽然在扩容,但工艺发展受限,因此可以看到大家对使用堆叠技术、容量密度高的HBM的需求增长迅速,还有显存与服务器内存需求也在不断增加。
再看闪存存储部分,AI服务器的算力单元成本里大概有60%-90%是计算单元,也就是GPU。而我们要做的就是活用算力单元,让它的使用率变高,降本增效。闪存存储方面需要承担的是避免停机的存储稳定性,还有高性能,让GPU务尽其用,以及节能和节省物理空间。
AI训练与推理全流程的存储需求剖析
从AI大模型的训练和推理角度来看存储。AI数据流的推动过程包括数据提取、准备(清洗、向量化)、模型训练(含检查点和恢复)、量化、微调、推理(结合RAG抓取实时资料)以及推理结果归档。整个流程与存储密切相关,不同阶段对存储的需求有所不同。
例如,数据处理、训练、微调使用闪存为介质的固态硬盘,数据摄取、归档通常搭配机械式硬盘(对象存储层),而且中间使用全闪存层作为缓存,既满足冷数据管理,也支撑热数据吞吐。
而且在模型训练阶段,存储的核心任务是提供训练数据来充分利用GPU资源,并保护训练投资。存储的关键能力包括高读取带宽(以减少GPU等待时间)、快速写入检查点数据(以便在系统崩溃时快速恢复)以及易于扩展。
推理阶段则需要高可靠性和短读取时间,以支持安全存储和高效批量处理。
在模型训练过程中,检查点写入器也与存储高度相关,用于保存中间数据以防止系统崩溃导致的训练中断。以175B参数模型为例,检查点大小约为2.45TB。若在2小时内完成2.5%的写入时间(180秒),则存储频宽至少需达到13.6GB/s。也就是说在评估存储媒介时,必须确保足够的频宽以满足训练需求。
检查点恢复部分同理,175B的参数模型,欲恢复的模型参数与暂态数据大小约为2.45TB。假设模型是16个实例并行数据读取,希望5小时内把数据写回来,就需要频宽是2.18GB/s,对存储的吞吐能力和稳定性提出了硬性要求。
在推理的存储架构中,需存储微调前后的模型数据,以及RAG数据。同时,推理完成后将提示词输入和结果输出写入存储。以往数据直接写入HDD(冷盘),但为提升用户体验,需引入硬盘缓存数据,将提示词输入和结果输出存储在SSD上,以便后续相似问题可直接从缓存获取结果,避免重复推理。例如,128K输入的首次Token延迟可从13秒降至500毫秒。因此,大容量SSD是理想的存储媒介。更适用于云端和一体机,可提升速度和用户体验。
从终端设备到边缘端,再到公共云混合型数据中心,整个流程涉及数据收集、模型训练、推理、信息收集和参数调整。大模型训练的数据需要结合RAG或实时资料进行更新,RAG数据库可部署在边缘端、核心数据中心或公共云。在落地应用时,需要进行整体规划,确保全流程的无缝衔接,从而提升系统效率和用户体验。
铨兴科技:应对AI存储挑战的创新实践
在AI训练与推理领域,铨兴推出一系列企业级SSD产品与解决方案,以应对行业挑战。
在企业级SSD产品方面,推出QLC PCIe 5.0企业级SSD,其最高容量达122.88TB,接口支持PCIe 5.0,还支持Dual Port,可靠性达10负18次方级别,适用于缓存、向量数据库RAG存储。其超高读速,超高容量,是AI 推理的最佳存储搭档。
高速TLC PCIe 5.0 SSD单盘容量达30.72TB,适合模型训练、HPC计算等高IO需求场景。其高读写效能的表现,是AI训练/HPC的存储优先选项
高DWPD SATA SSD在SATA接口上实现最高15.36TB容量与3 DWPD写入耐久,远超行业平均0.5-1DWPD的功能特性。
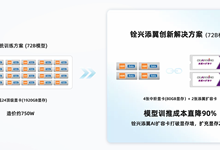
在AI训练一体机解决方案上,铨兴带来添翼AI扩容卡方案。该方案有效解决大模型训练中“显存不够、成本太高”的痛点,原本训练DeepSeek-R1 671B模型需168张顶级GPU,使用16张中端GPU加上8张添翼扩容卡就能完成同等训练,成本从4200万降至200万以内,降低约90%。另外,单张GPU卡PC加1张添翼卡可训练14B模型,四张GPU卡工作站加2张添翼卡可达72B模型。
该方案已广泛适配英伟达、天数智芯、沐曦等国产显卡,并与厦门大学、贵州大学、广州大学等高校合作部署实测,适用于要求高精度、全参数、70B及更大模型微调训练的本地化部署等场景。
最后
邱创隆强调,大模型时代不仅需要更强的中心计算能力,更需要覆盖终端、边缘、公有云的多层级协同存储体系。
无论是实时抓取RAG数据库、还是模型分发/回写、还是训练检查点的写入恢复,都需要高性能、高容量、低功耗的存储设备提供强力支撑。