2025年4月8日,斯坦福大学以人为本人工智能研究院(HAI)发布的《2025年人工智能指数报告》(以下简称“报告”)引发全球关注。这份长达456页的年度报告,以详实数据揭示了人工智能领域的关键趋势:中美AI竞争从“量”到“质”的格局转变、开源模型的崛起、硬件效率跃升引发的成本革命,以及AI技术对社会经济的深度渗透。
文字编辑|宋雨涵
1
中美竞争最新态势
性能差距缩至毫厘,但生态差距仍存
报告最引人注目的结论是,中美顶级AI模型的性能差距从2023年的20%以上大幅缩小至2024年的0.3%,尤其在MMLU(大规模多任务语言理解)、HumanEval(代码生成)等核心基准测试中,中国模型几乎与美国顶尖产品持平。以DeepSeek-V3为代表的中国开放权重模型,在推理效率上甚至逼近闭源巨头,其与闭源模型的性能差距从2024年的8%缩小至1.7%。
然而,数量差距仍是现实:2024年,美国机构开发了40个重要AI模型,远超中国的15个和欧洲的3个。过去十年,美国累计开发的机器学习模型数量仍居全球之首。这一矛盾背后,反映的是两国AI生态的差异:美国以企业主导创新(90%的重要模型来自产业界)
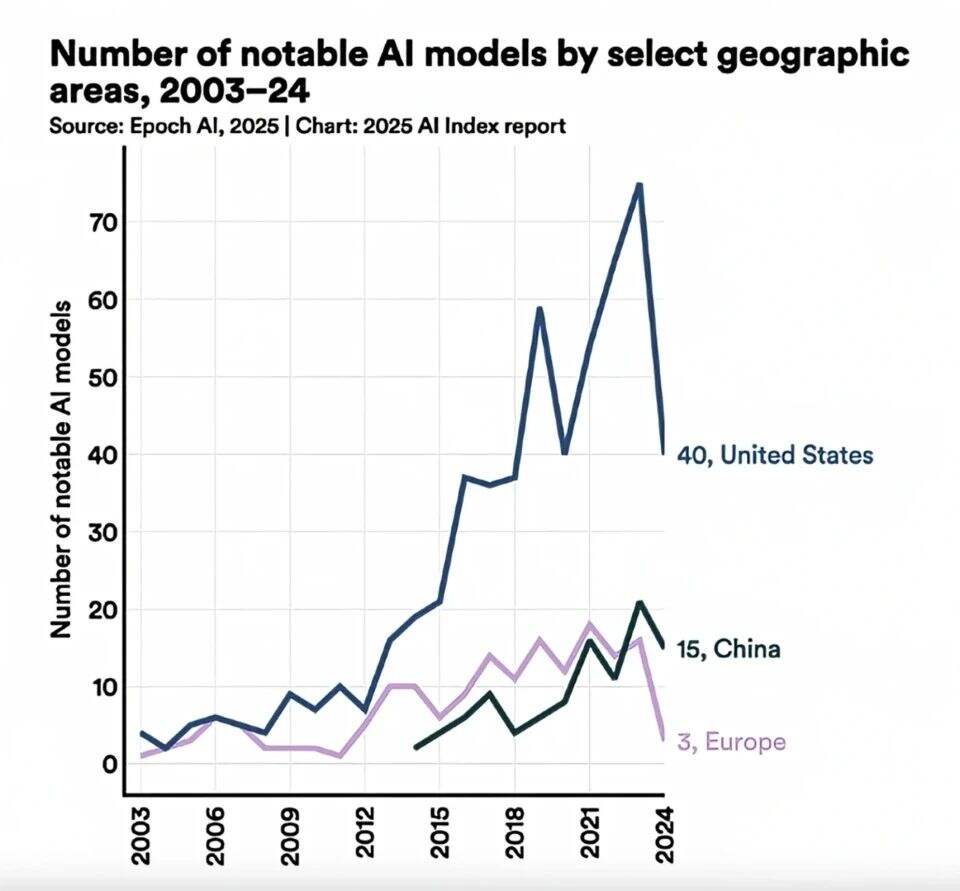
图:重要AI模型数量
而中国在论文数量(全球占比23.2%)和专利授权量(全球69.7%)上领跑,但高影响力研究仍由美国主导(Top100高被引论文中,美国贡献50篇,中国34篇)。
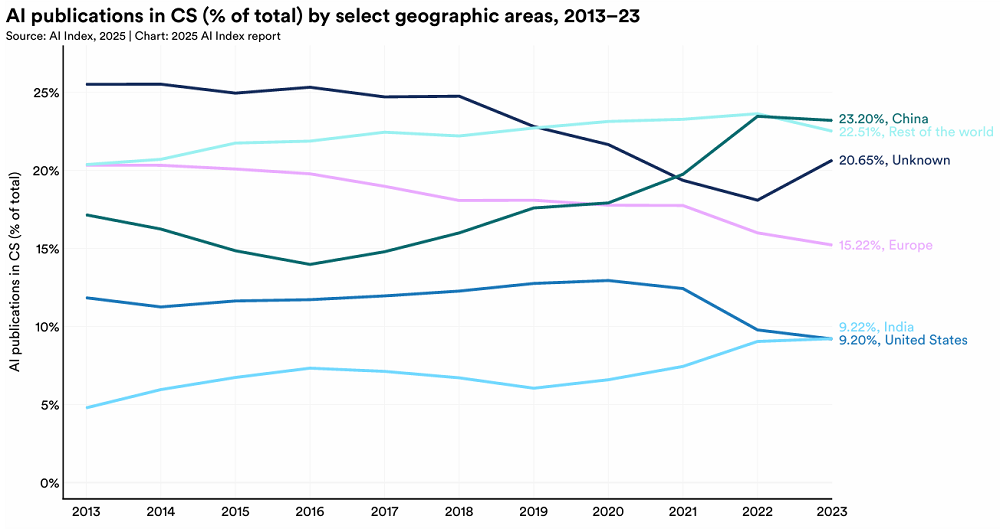
图:论文发表数量
2
技术突破
DeepSeek率先打响成本革命
通过混合专家架构(MoE)与动态路由优化,将170亿激活参数动态分配给128个专家模块,仅需激活必要模块即可完成任务,避免“全参数启动”的资源浪费。DeepSeek-V3的推理成本降至$0.07/百万token,仅为GPT-4的1/10。其训练能耗较Llama 3下降62%,单卡H100即可运行,彻底打破“算力即霸权”的行业铁律。
小模型迎来性能突破
2022年时,能在MMLU多任务语言理解基准测试中达到60%准确率的最小模型是拥有5400亿参数的PaLM。
而到2024年,微软仅38亿参数的Phi-3-mini模型就实现了同等表现,两年间模型体积缩小了142倍。
AI使用成本呈下降趋势:
图注:从2022年到2024年,GPT-3.5和GPT-4在基准测试中的推理价格呈下降趋势
以GPT模型为例,对于MMLU测试中达到GPT-3.5水平(64.8%准确率)的模型,单次百万token查询成本从2022年11月的20美元,暴跌至2024年10月的0.07美元(Gemini-1.5-Flash-8B模型),18个月内降幅超280倍。不同任务的LLM推理价格年降幅达9-900倍不等。
经济影响:
企业降本增效加速,生成式AI成资本宠儿
AI对生产力的改造已进入规模化阶段:
企业应用爆发:78%的组织在2024年采用AI技术,较前一年增长55%。中国大陆企业AI采用率达75%,与北美差距缩小至7%。
投资热潮:2024年全球AI投资达2523亿美元,其中美国以1091亿美元领跑(中国为93亿美元),生成式AI独占339亿美元,年增长18.7%。
值得注意的是,尽管投资回报尚未全面显现(多数企业成本降幅低于10%),但生成式AI在医疗、金融等领域的商业化潜力已初露锋芒。例如,FDA批准的AI医疗设备数量从2015年的6款飙升至2024年的950款,AI在蛋白质折叠预测等科学任务中甚至助力研究斩获诺贝尔奖。
AI竞赛的“中国式突围”能否持续?:
中国政府在AI领域给予了大力支持,成立了国家数据局推动数据要素市场化,全面落地“东数西算”工程降低算力成本。这些政策红利为中国AI企业的快速发展提供了有力保障。此外中国AI企业积极构建开放生态,推动产业链上下游协同发展。华为“鲲鹏+昇腾”算力底座、百度“文心一言”开放平台、腾讯“混元”大模型产业联盟等,为AI技术的研发和应用提供了有力支撑。但是中国AI的发展还面临着基础研究断层的问题:若无法在算法、芯片等底层领域突破,中国可能陷入“应用强、生态弱”的被动局面。而且要面对开源与商业的平衡:过度依赖开源可能导致核心技术创新动力不足,从而难免走“下坡路”,“中国式突围”能否持续?让我们拭目以待吧!
结语
斯坦福报告描绘了一幅复杂图景:技术差距的缩小并未消弭生态系统的差异,效率革命催生了普惠红利,对中国而言,如何在基础研究、算力自主与商业化落地之间找到平衡,或将决定其能否在下一轮康波周期中实现从“追赶”到“引领”的跨越。而对于全球,构建负责任的技术生态,或许比单纯追求性能突破更为紧迫。