
生成式AI技术应用的快速发展,对分布式数据存储设计提出了新的需求,在3月27日举行的“2025人工智能基础设施峰会”上,浪潮数据张在贵从专业技术的角度对此进行了解读。
张在贵表示,对于生成式AI技术应用,不能把目光仅仅着眼于大模型的训练与推理,而是要从整个数据生命周期的角度、从AI场景的数据架构和IO特征上进行深度定制,提供专业的技术支持和服务。

生成式AI应用的不同阶段,特点和要求也有所不同。以数据归集和准备阶段为例,其要求的是千亿级、百PB级存储空间的支撑。多模态大模型依赖海量文本、图片和音视频资源,这个阶段需要关注多协议归集和异构存储统一纳管;训练阶段需要关注CheckPoint写入和读取带宽的问题,解决 TensorFlow 开发框架中TFRecord数据格式中的小IO文件随机读写性能不佳的问题;而推理阶段要关注高效KV Cache管理问题,以期减小重复计算,从而提升推理速度和并发性。
浪潮数据将这些问题概括为“横向高效流动,纵向高速访问,联合上下游建生态”,并提出面向场景的深度定制和优化的理念。
横向高效流动涉及多协议融合以及全局文件系统设计问题。以多协议融合为例,其主要追求的是数据和元数据在存储池中只存一份,实现S3、HDFS和NAS多协议访问互联互通。简单来说,就像一瓶汽水安排了多个吸管。基于生成式AI的数据局部性原理、相邻数据可能被访问的特点,元数据组织采用范围分片替代哈希分片。通过这一设计,数据在存储介质上以连续存储或邻近存储形式呈现,可以显著提升预取效率和缓存机制命中率,从而减少磁盘I/O操作次数,提高AI训练和推理的效率。
与横向流动相比,纵向高速访问则更为大家所熟悉。英伟达的GDS(GPU Direct Storage)本质是NVMe和RDMA技术的结合,目的在于减少CPU参与带来的时延,追求更高效的数据访问。因此,RDMA、NoF(NVMe over Fabric)都是必须要考虑的设计因素。对于提高GPU访问外部数据存储的效率,这些技术立竿见影。

针对AI场景的小IO随机读写,全局缓存也是数据纵向高速访问的重要因素。涉及小I/O访问,需要写入Cache并在Cache中做小I/O聚合,变随机写为顺序写,从而大幅提升节点随机小I/O写入性能;考虑到分布式存储的多副本设计,节点间副本若采用单边RDMA技术,数据同步无需对端CPU介入,就可以实现延时降低50%、CPU节约20%的目标。
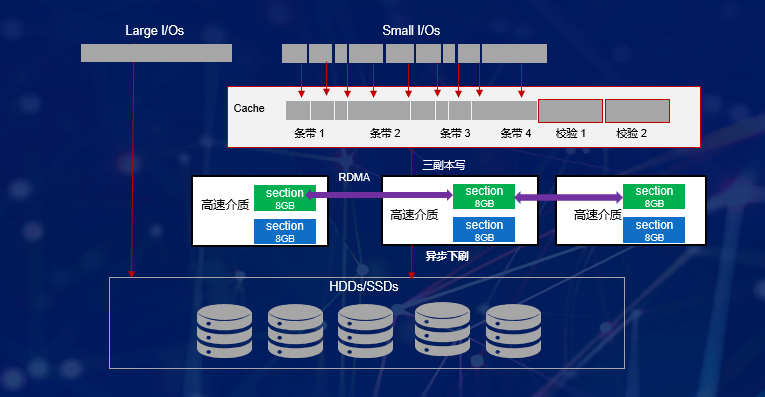
此外,针对创新CPU应用,还需要充分考虑芯片的设计特点,扬长避短,发挥其优势和特性,如减少双路CPU之间的数据转发等。

充分考虑到生成式AI的这些特点,浪潮数据存储通过场景化定制策略采用有针对性的技术方案,在MLPerf™ Storage v1.0机器学习工作负载下存储性能国际基准测试中,获得了5项第一、3项第二,综合成绩全球第一的成绩。
正如3FS针对DeepSeek训练的深度定制,浪潮数据依托完整的研发体系和团队联合上下游针对AI甚至更广阔的场景进行深度定制,为最终用户提供更好的解决方案。







