
秋风一起,眼见2010年就要过去了。去年这个时候,大家还在展望32纳米的新酷睿Westmere 处理器–第一颗了 "吞并"了主流GPU(图形处理单元,显卡核心)的CPU。而大家今天的话题则更多的转向英特尔新一代的架构Sandy Bridge,其中的亮点之一就是显示核心(GPU)的全新实现方案–无缝融合。在业界继续保持这种融合技术的领先。
2010年初发布的新酷睿处理器(Westmere)采用的方案是32纳米的CPU核心加上45纳米的GPU核心。拆开Westmere 处理器的封装可以清楚地看到CPU+GPU的 "1+1"两个核心的组合。
明年第一季度将要发布的Sandy Bridge 则做的更彻底,这个新的处理器微架构不只是 "吞并",而是把GPU "消化"并融入CPU芯片中,成为自己身体不可缺少的 "一部分"。 用户购买了这样的CPU,同时也就拥有主流性能的"显卡"了,显卡以一块"卡"的形式存在于电脑中也越来越无形了。特别是笔记本电脑,用户不再为以往的集成显卡性能不佳而烦恼,也不用为焊上独立显卡芯片的笔记本电脑太热太吵以及电池迅速耗尽而苦恼。因为融合于CPU之中的核显,具有更高更智能的性能和更精良的能耗管理,以及和CPU其它计算单元之间更协调的均衡计算。
从 "图一"可以清楚地看到,一颗4个物理核心的Sandy Bridge处理器具有一个核显(GPU)了,它已经是CPU芯片的整体不可分割的一个部分,同样采用英特尔最先进的32纳米处理器制造工艺来实现。如果有机会拆开Sandy Bridge的处理器封装,我们所看到将是浑然一起的一颗32纳米芯片,GPU完全融合在CPU之中,非专业人士已经很难区分哪个区域是原来的CPU主要单元,哪个部分是GPU。
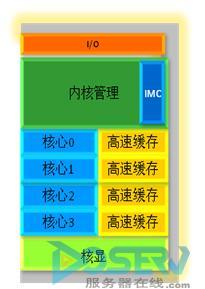
图一: 核显融合在Sandy Bridge 处理器中
在 "图一"中,4个物理核心、核显、内核管理、内存控制器(IMC)等等都可以使用最后一级的可共享的高速缓存,具体实现中这级高速缓存就是我们所熟知的三级共享的英特尔智能高速缓存。图中看到高速缓存分成了4个部分,不要误解它们是每个核心专属的一级和二级高速缓存,图中没有细化到把核心0到核心4的一级和二级高速缓存都画出来。图中所示的是共享的三级高速缓存,它被分成物理上的4个片段,逻辑上由处理器内部的各个核心单元共享。
既然融为一体,Sandy Bridge中的核显(GPU)带来的优势是之前的酷睿处理器(Westmere)中的GPU不能比拟的:Sandy Bridge的核显可以直接使用共享的三级高速缓存了,它与各个核心能够直接在高速缓存交换数据而不仅限于之前的系统内存。因此,我们称之为 "核芯显卡"就更为贴切。也就是我们图中简称的 "核显"。
Sandy Bridge 中还设计了创新的高速环形联通架构,各个核心、各个高速缓存段、核显、内核管理中心等等可以通过这个高速的双向环形架构进行数据的交换。图二可以看到这个环形架构将Sandy Bridge 内部的各个单元连接起来,其中核显就是这个环形联通架构上的重要一个节点。
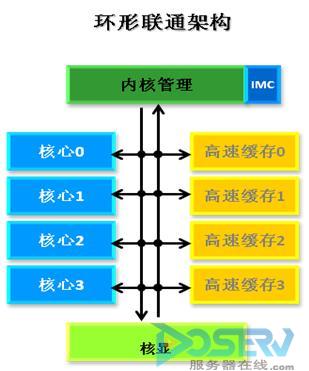
图二:Sandy Bridge的环形联通架构
Sandy Bridge融合架构让我们看到这样几个趋势:
(1) 采用CPU的制造工艺,融合的GPU(显卡)的性能将得到进一步的提升,它的发展和CPU休戚以共,共同进退。(2) GPU从此成为CPU的标准单元,CPU的定义拓展了,具有主流图形能力和性能的CPU将是常态。反之,没有GPU单元(没有显卡功能)的CPU将成为 "前辈"。(3) GPU 单元在CPU的核心设计中将继续融合,边界更加模糊,甚至在指令集上进行融合和相互补充。(4) 中高端独立显卡将在高端应用上继续存在,但是主流市场的退缩已经在所难免了。(5) 只要摩尔定律继续有效,CPU作为中央处理单元将继续融合更多目前还是独立的单元。







