大数据这一概念的存在已有些时日,不过其滥用程度快超过了“云”
有趣的是,一些大型的传统存储供应商正接受这一概念,似乎这个名词已经成了大型数据集及其产品的代名词。大数据实际上与传统存储供应商的技术和商业模式都成对立关系。
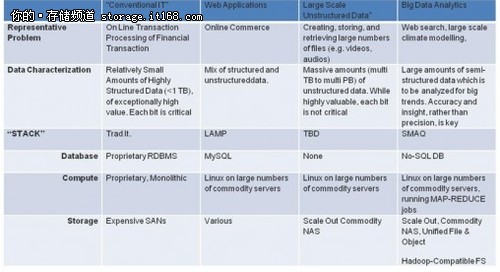
一个正在形成的共识是:大数据不仅仅是指大量数据,而是特指无法用传统方法处理的大型数据集。那么这里所说的传统方法是指哪些呢?要回答这个问题,就要看一看这些方法本来是为了解决什么问题。
在企业IT历史中,最大的问题是确保传输系统顺畅,快捷且准确地运行。这一需求为IT打开了一条通道,即专属整体服务器上部署专属关系型数据库。
当规模较小,具有较高价值且结构化的数据遭遇威胁要崩溃时比较适合选用传统IT堆栈。例如,Web规模应用就推动了LAMP堆栈等需求,它可以满足运算分布并在大量商业服务器上提供服务。同样,非结构化数据的爆发式增长导致存储硬件相同的商品化需求。
某种程度上,大数据意味着整个传统IT堆栈的挑战——即数据库,运算和存储。这就是为什么需要新堆栈(存储,MapReduce和Query)的原因。正如LAMP堆栈对IT的转变,笔者相信大数据SMAQ堆栈也会改变IT。
想象一下,假如你不仅能够保存和服务十多亿份文档,还能够对这些文件执行复杂的分析,例如分析文件之间的关联模式。许多现有与大数据相关的技术来自于大型网络公司处理这些问题的项目。
假设,你不仅仅需要保存上百万份与天气数据相关的文件,还需要分析与气候改变模式相关的数据。那么问题不仅仅涉及大量数据的保存,还需要利用那些对模式和趋势有研究意义的数据。
传统数据库远不止上述任务。各种设计的局限性使得关系型数据库处理问题的能力很出色,如保留传输记录限制了数据库的扩展能力。幸好,上述分析通常不需要绝对的精确度。
同样,传统存储和运算也不止这个任务。上述分析和存储最好是通过将数据和存储分配到大量商业存储设备上执行,再将运算分配给大量运算设备完成。你或许可以想象得到,输入数据按顺序在所有分布式设备上进行处理,然后传送到中间数据集。这些中间结果会精简到一个数据集中,而这个概括性的数据集就是所需的最终结果。这两个过程分别叫做Map和Reduce,在SMAQ的首字母缩略语中标记M。
最近我们看到了首字母为M,A和Q的技术涌现出来。对于开源爱好者而言,最令他们激动的事情就是关注Hadoop生态系统。
如我们常常看到的,存储需要匹配剩余的IT堆栈。数据集本身需要高度分布。数据和大数据的运算出现在种类繁多的分布式设备上。
而且,由于将运算导入数据比将数据导入运算要容易,所以SMAQ堆栈的存储部分需要确保所有未结构化数据和半结构化数据的安全而有效地分布到所有运算节点,且既可以被扩展也可以满足高性能的要求。这意味着大数据必须:
a) 在广布于互联网的各种商业设备上运行
b) 为与分析相关的密集式数据处理提供性能帮助
c) 避免设计失误,如集中式元数据存储以及大量遗留系统将存储大小限制在16TB
d) 允许在相同硬件上出现运算和存储功能。综上所述,将运算迁移到存储的成本更低。不过如果存储被锁定那就会有些麻烦。
e) 扩展至PB级别甚至是EB级别。
结论:专属与整体的存储方法不适合大数据。不过,随着大数据SMAQ技术的不断发展,相信大数据存储和存储效益方面的价值会被充分地释放出来。