利用赛灵思 FPGA 的动态重配置功能,同构多线程执行模型可同时兼得软件灵活性和硬件性能。
一台在未知的土地上行进的自动机器人;一部能够根据信号强度改变解压缩格式的视频解码器;一套宽带电子对抗系统;一种用于机动车辆的自适应图像跟踪算法……这些都属于大量涌现的随环境瞬变做出快速响应的新兴嵌入式或者关键任务应用。在过去,静态决策最坏情况分配曾为严格的实时约束提供了解决方案,而现在灵活性也成为一项要求。法国某研究项目建议使用的解决方案是一种分布在 FPGA 资源上,对软硬件线程进行管理的操作系统。
我们的目标是设计一种支持新的系统分区类型的架构,让软/硬件组件遵循同一执行模型。这就要求高度灵活的可扩展操作系统。
近年来,特别是在嵌入式系统中,随着片上系统 (SoC) 密度的增大,可以通过并行处理任务和数据,来增加运算单元,最终满足设计约束的要求。目前,随着异构计算内核的加入,这种趋势仍在继续。不过这种技术遇到了难以逾越的复杂性障碍,因为它需要对编程模型进行更高层次的抽象。
为了攻克这些难题,我们建议定义一个统一的执行模型,不管线程是映射到硬件还是软件上都可以使用。该执行模型的硬件实现高度依赖动态可重配置逻辑的使用。全分布式架构结合传统多核软件子系统,可同时兼备软/硬件的优点。软件部分很适用于智能化事件控制和决策,而硬件部分则擅长于提高能效、吞吐量以及数字运算。通过两者的结合,无论是针对每种特定的应用,还是针对某一应用的某一特定状态,我们都能在性能与资源利用率之间实现最佳平衡。
新型 FPGA 平台具有高度的灵活性和可扩展性,且集成度高,能够在单个或两个芯片上集成一个完整的异构动态运算系统。
自适应硬件在诸如导弹电子和软件无线电等功耗和系统尺寸有限,同时对环境高度敏感的应用中非常有用。采用动态重配置技术,可以在不增加系统功耗或电路板尺寸的情况下,实现支持不同应用模式的专用架构。传统解决方案侧重于控制部分,现在看来似乎已经不能有效地满足执行单元的数量及其异构性要求。只有采用兼具灵活性和可扩展性的分布式方案,才能够创建出面向未来的架构。
虽然这种技术潜力无限,但对整个业界来说,动态重配置的使用仍然有相当大的难度。工程师需要一种清晰明确的设计方式,既能够充分地发挥动态重配置的优势,又不影响应用描述,而且最重要的是,不增加开发成本。为了将动态性和高性能结合起来,我们建议采用基于多线程的执行模型对异构性进行抽象。开发人员可以将应用当作线程集来进行编程,而不必考虑线程是在标准处理器还是专用硬件上执行。在这种情况下,动态重配置的作用是进行线程优先调度(thread preemption)和上下文切换。由法国国家研究署 (French National Research Agency (ANR)) 赞助的 FOSFOR(灵活的可重配置平台操作系统)项目就专门负责开发这种新一代嵌入式、分布式实时操作系统。
FOSFOR 架构基础
我们的目标是设计一种支持新的系统分区类型的架构,让软/硬件组件遵循同一执行模型。这就要求高度灵活的可扩展操作系统,能够为软件域和硬件域提供相似的接口。与传统方法不同,这种操作系统是完全分布式的,整个平台从应用的角度来看是同构的。这就意味着既能以静态方式,也能以动态方式在软件(处理器)或者硬件(可重配置单元)中部署应用线程,对分布式服务进行无差别的访问。
为了实现高效率,我们在紧邻可重配置区的硬件中实现操作系统服务。我们在异构操作系统内核之间实现了一个通信层,以确保从应用角度看服务是同构的。因此,将操作系统当作大量模块和执行单元部署在架构上,可以充分发挥虚拟化机制的优势,从而使应用线程在未预知任务的情况下运行和通信。
从编程人员的角度来看,该应用只是个线程集。我们可以利用赛灵思 FPGA 的动态重配置功能来提议这种硬件线程的新概念,同时也可采用与软件线程相同的方式来实现这一概念。我们的实现方式充分发挥了专用计算 IP 模块的性能优势。
除了要考虑到多处理器 SoC 中的执行单元,存储器结构还必须满足以下几项要求:应用线程需要的数据存储、每个线程执行上下文的存储以及线程间的数据交换。对于执行上下文的存储,我们认为有多种可能性。一种方式是集中存储执行上下文,这样为将其分配到不同执行单元提供介质。我们可以确认平台内的三种通信流:应用数据、控制信号和重配置/执行上下文。对于硬件线程之间的高带宽数据路径,我们使用专用的片上网络 (NoC)。
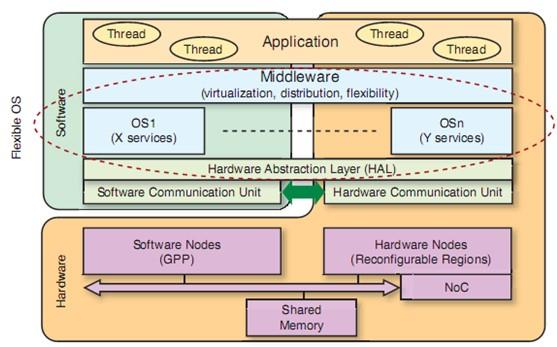
图 1:通用 FOSFOR 架构
图中文字:
灵活的操作系统 软件 线程 应用 中间件(虚拟化、分布、灵活性) 操作系统 1(X 服务) 操作系统 n(Y 服务) 硬件抽象层 (HAL) 软件通信单元 硬件通信单元 硬件 软件节点 (GPP) 硬件节点(可重配置区域) 片上网络 共享存储器
全局架构
全局架构如图 1 所示,其组成包括:
l 一系列非专用(通用)处理器 (GPP)。GPP 负责支持软件线程的执行,以及包括线程调度在内的一系列操作系统服务。GPP 在指令集架构和提供的服务数量方面不必同构。
l 一系列动态可重配置分区(也称可重配置区域 (RR))。动态可重配置分区负责并行或串行执行一系列硬件线程。与 GPP 相似,由于采用硬件操作系统 (HwOS),RR 也支持操作系统服务的执行。这些区域对应着精粒度 (FPGA) 或粗粒度(可重配置处理器)架构。
l 共享着一条或多条物理通信通道的虚拟通信通道,用于控制、数据和配置。控制通道负责把操作系统服务之间的通信分配给执行单元(GPP 和 RR)。数据通道负责传输与环境(器件、传感器)有关的信息和线程之间的信息交换。配置通道负责在配置存储器和执行单元之间传输软件线程(二进制代码)和硬件线程(部分比特流)的配置。
每个处理器都有自己的本地存储器。该存储器负责存储本地数据,在适用的情况下,也可存储软件代码。连接到数据通道的共享存储器可以实现不同处理器上线程间的数据共享。每个执行单元都可以访问共享存储器上存储的数据和软件执行资源程序。每个资源还可以访问配置存储器,以保存和恢复其执行上下文。采用这种结构,可以在任何执行资源上实现任何线程或服务。
在 RR 内部,只有硬件任务需要动态重配置。负责托管任务的动态区域 (DR) 被包含操作系统服务硬件实现的静态区域 (SR) 所包围,同时在 RR 内外部提供通信介质。内部数据流通信依靠专用的片上网络。DR 和 SR 之间的接口采用总线宏并且有固定的位置。为实现该约束以及通信介质异构性的抽象,我们采用中间件方案来提供到可重配置分区的虚拟访问。RR 根据图 2 中定义的模型构建。FOSFOR 原型平台由能够直接支持这种架构模型的动态可重配置 FPGA 器件构成。我们选用了 Virtex-5® 器件,因为其能够重配置矩形区域。
我们根据预先测算的应用线程资源需求定义了调度/布局算法,以确保每个 RR 中 FPGA 元件(LUT、寄存器、分布式存储器、I/O)的高效利用。
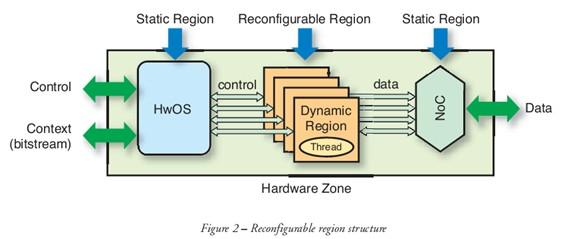
图 2 — 可重配置区域结构
图中文字:
控制 上下文(比特流) 静态区域 可重配置区域 静态区域 数据 硬件操作系统 控制 动态区域 线程 数据 片上网络 硬件分区
操作系统、片上网络及中间件
为具备灵活性,FOSFOR 架构使用了至少两个操作系统实例:一个为运行在每个处理器上且负责处理软件线程的软件操作系统;另一个为能够管理硬件线程的硬件操作系统。为了在性能、开发时间以及标准化之间实现最佳平衡,我们使用了现有的软件操作系统和全新的硬件操作系统。
该硬件操作系统利用赛灵思 FPGA 的动态部分重配置功能,在调度硬件线程方面与传统操作系统调度软件线程一样灵活。
对软件操作系统的要求是实时行为、能够处理多个处理器并提供基本的进程间通信服务。我们选用了一个免费的开源操作系统 RTEMS(实时多处理器系统,请见 http://www.rtems.org/)。出于兼容性原因,我们选用了 LEON Sparc 软核处理器,同软件节点一样,其也是免费和开源的。
该硬件操作系统(HwOS)利用赛灵思 FPGA 的动态部分重配置功能,在调度硬件线程方面与传统操作系统调度软件线程一样灵活。硬件线程由动态和静态两大部分组成。动态部分内含一个用来执行线程功能的 IP 模块和一个用来使服务调用次序与硬件操作系统同步的有限状态机。静态部分则内含一个与硬件操作系统相连的控制接口和一个用于与其它软硬件任务进行交换数据的网络接口。
为支持多种线程间数据传输需要,我们开发出了一种灵活的片上网络 DRAFT。传统操作系统的通信服务足以支持软件线程间的通信。但在我们的设计中,操作系统还需要支持硬件线程间的通信。为此,我们专门设计了 DRAFT 网络。我们针对一个或者多个 DR 逐一综合硬件线程,同时静态地定义每个 DR 接口。
通信接口的静态定义让我们可以定义静态的片上网络。一般来说,硬件线程要求高带宽和低时延,故片上网络必须提供高性能。我们为 DRAFT 选择的拓扑是一种胖树拓扑的扩展。我们设计的主要目的是为了限制资源开销,同时实现高性能的线程间通信。
硬件平台的异构性是设计人员部署应用时面临的主要的复杂性障碍。在 FOSFOR 项目中,这种异构性不仅来自软件域中的不同嵌入式处理器,还来自在单个平台上同时集成软件和硬件计算模型的做法。
采用中间件在硬件和软件间建立抽象层,并提供同构编程模型,可以很好地解决这一问题。中间件实现了一组虚拟通道,可以在不必理会线程的实现区域的情况下进行线程间通信。这些服务跨平台分布,提供了一个灵活的可扩展抽象层,让 FOSFOR 构想臻于完善。
性能加速
构建硬件操作系统的主要原因出于性能和灵活性方面的考虑。该操作系统本可以采用纯软件或纯硬件。由于每次调用操作系统原语都会涉及开销,即线程等待时间,操作系统速度越快,浪费的时间就越少。为了评估开销,我们必须就硬件操作系统的时序和原始的软件操作系统 RTEMS 做一比较。
硬件本地运行只需要数十个周期,而为了访问共享存储器,硬件全局运行需要数百个周期。经我们评估,与软件操作系统的运行结果相比,本地创建-删除操作速度提高了 60 倍,其它操作速度也提高了约 50 倍。
硬件操作系统的资源使用(表 1)相差较大,这主要取决于激活的服务的数量及功能,比如我们为每项服务选择对象(信号量、线程等)的数量。我们使用赛灵思 Virtex-5 FX100T 来实现系统。表中列出了硬件操作系统使用的资源。余下的资源可用于实现其它系统组件及硬件线程自身。
|
实现的结构数量 |
8 |
16 |
32 |
|
CLB Slice |
2,408 (15%) |
3,151 (20%) |
4,327 (27%) |
|
D 触发器 |
5,498 (8.5%) |
6,650 (10.4%) |
8,918 (13.9%) |
|
BRAM |
8 (3.5%) |
16 (7%) |
32 (14%) |
表 1 — 硬件操作系统 (Virtex-5 FX100) 的资源使用情况
对于网络性能,在 DRAFT 连接 8 个32 位字宽、缓冲深度为 4 个字,频率为100MHz 的组件的配置下,片上网络可使每个连接的组件的最大数据速率高达 1,040Mbps。网络的拓扑和路由协议保证不会出现争用和拥堵现象。在两个互连的组件间,至少一直保留着一条通信路径。数据通过 DRAFT 的平均时延接近 45 个时钟周期(450 纳秒),这符合许多应用的要求。
展望
我们提议采用一种创新型的操作系统,可以在由多个处理器和动态可重配置硬件 IP 模块构成的异构多核架构上提供基于多线程的同构执行模型。硬件操作系统负责管理硬件线程,一般用于线程创建和抑制,以及信息量和消息队列服务。在通信方面,我们建议改进用于数据交换的胖树拓扑片上网络、用于硬件线程管理的专用总线以及为实现操作系统间同步的通信层。
从行业角度来看,下一步是演示为确保执行模型的同构性而添加的硬件的功能,这可以真正提升编程效率,同时还能在专用 IP 模块上保持较低性能开销。
我们将在一个代表性的、基于搜索跟踪算法的泰雷兹公司应用上演示我们的方法。跟踪线程将被映射到可重配置分区,并根据目标探测情况动态地创建。