
It is Coming。我已经激动得很难用言语来表达此刻的心情。在压抑了这么久之后,我们期待已久的英特尔最新一代双路处理器产品终于与大家见面了,也就是今天我们要介绍的至强E5-2600系列。

Intel发布Sandy Bridge微架构32nm至强处理器
按照英特尔著名的Tick-Tock战略,新一代的至强E5-2600系列还是沿用了之前单路至强E3所采用的SandyBridge架构,但是因为E5是面向双路应用的产品,所以在命名上叫做“SandyBridge-EP”。作为英特尔的主力产品,至强E5依然采用的是32nm工艺,这一点是肯定的,因为更低规格的22nm IvyBridge处理器要到下半年才能上市,至于服务器版的上市时间更要拖后一些。由此判断,至强E5是今年英特尔在服务器市场中的主打型号,它的新出现必然是要取代2年前发布的Westmere-EP产品(也就是我们说的至强5600系列)。
等待了这么久,我们将要为大家介绍的是至强E5-2600系列的最新特点。但是在介绍之前,我们希望大家能够有点时间稍微熟悉一下SandyBridge架构的特征,这样可以更好的理解E5-2600系列在双路应用中的特性,及英特尔在实现多处理器互联互通中的努力。以下两个文章都是针对SandyBridge架构进行的详细介绍。
Intel至强Sandy Bridge处理器首发评测
不看不知道 一句话解读SNB平台4大革新
如果你能够很好的理解至强E3的SandyBridge架构,那么你可以将至强E5-2600看作是E3的双路或者威力加强版。我们先来看看下面这个架构图,图中标红的部分代表了E5-2600系列的革新之处。

至强E5-2600处理器架构介绍
图中为我们传达了4个重要的信息——8核心、第二条QPI通道、DDR3高频内存的支持、PCI-E 3.0互联互通。下面我们就一一来解释这4个要素。
8核心处理器——在上一代的Westmere-EP处理器中,某些高端的型号采用的是6核心架构,这也是英特尔在双路处理器中提供的顶级核心数量。当然借助于超线程的支持,这个核心数量的数字可以翻一番,但是从物理的角度来说英特尔在E5-2600之前一直是以6核心的产品担当重任。
如今发展到了E5-2600系列,处理器的核心增加到了8个。这个不仅仅是简单的数量提升,要知道在同样适用SandyBridge架构的E3处理器中,核心数量只有4个。更多的物理核心可以提供更好的计算性能,当然对于时下流行的虚拟化来说,多核心的优势更为明显(这也是为什么AMD要推出16个物理核心的Bulldozer)。
第二条QPI通道——同样对比上一代的Westmere-EP处理器,英特尔自从在Nehalem-EP中增加了QPI这个概念之后,一直都是提供了单一的通道(可以双向传输)。而这次在E5-2600中,通道的数量增加到了2条,而且带宽也提升到了8GT/s,之前是6.4GT/s。换句话说,同样是基于SandyBridge架构,双路的产品比单路产品增加了更多的处理器互通功能,这会使得两个或多个处理器之前的协调更为顺畅,言外之意就是性能也会随之提升。
DDR3高频内存的支持——从Nehalem-EP开始,英特尔支持三通道的DDR3内存,那时候的频率还是1066MHz。到了Westmere-EP这代,三通道的内存支持没有变,但是频率提升到了1333MHz。如今,至强E5-2600这代产品出现了变化。首先是对于内存频率的支持达到了1600MHz,这还不是最重要的——至强E5-2600系列支持4通道内存,最大内存插槽数量也从原来的18条增加到了24条。从数量来说,3*6和4*6的看起来是多了不少,但是能够实现的通道组数量是相同的。当然,在这一代的内存上也有了明显的变化,这一点我们随后会提到。
PCI-E 3.0互联——英特尔在至强E5处理器中增加了对于PCI-E 3.0规范的支持,但是这一代的主板还仅能提供PCI-E 2.0的接口。在可以预见的下一代IvyBridge处理器中,英特尔将全面支持PCI-E 3.0规格。这部分我们在后面会有详细的解释,这里先给大家留下一个印象。
刚刚我们看过了至强E5-2600系列处理器的新改进,这还远远不够。我们需要了解的是E5-2600处理器是如何运行的,具体来说就是如何与其他的设备相沟通。这部分我们来看看下面的一张图。
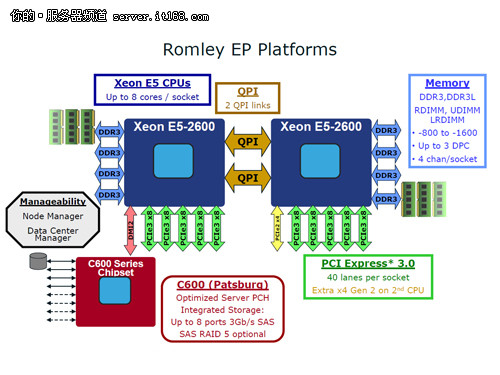
至强E5-2600处理器是如何运行的
首先来解释一个名词——Romley。Romley是本次至强E5处理器的平台名称,是围绕着至强E5处理器而开发的芯片组、主板以及相关技术组成的解决方案平台。因此,这里我们就可以看到这个平台在运行中的一些特性。
基本上处理器部分包括了我们刚刚介绍的内容,我们可以从图示中清楚的看到处理器所提供的40条PCI-E 3.0通道之外,在第二颗处理器上还有1条PCI-E 2.0的通道(黄色部分),第一颗处理器有粉色部分都与芯片组相连。
另外我们看到了两个英特尔一直力推的内容,Node Manager节点管理器和Data Center Manager数据中心管理软件。今年开始DELL在自家的服务器软件中使用节点管理器功能,这也是为数不多使用这个功能的厂商。
刚刚我们看到的还是以处理器为主,包括如何与外部互通的内容。那么处理器内部是如何通信的呢?这里我们就不得不提及它的核内与核外架构。
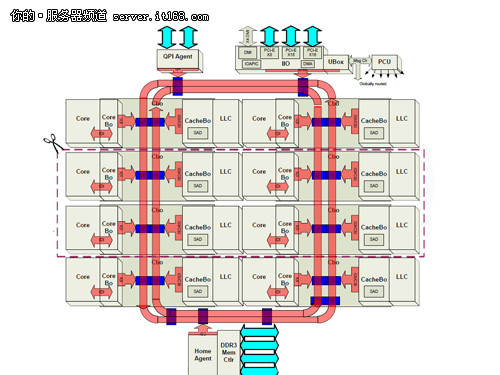
至强E5-2600处理器核内与核外架构
这里我们又看到了“圆环套圆环”的设计,也就是从SandyBridge开始的环形总线。与至强E3所提供的类似,这次的环形总线还是分为内外两条,在核心数量上增加到了8个。图中剪刀的部分就是至强E5相比E3来说增加的4个核心。
和E3处理器类似,Ring Bus环形总线更能够较好的展示出Sandy Bridge的真实性能。通过上图大家可以看到,Ring Bus环形总线连接各个CPU核心、LLC缓存(L3缓存)、融合进去的GPU以及System Agent(系统北桥)等部分。
Ring Bus环形总线由四条独立的环组成,分别是数据环Data Ring、请求环Request Ring、响应环Acknowledge Ring和侦听环Snoop Ring。借助于环形总线,CPU与GPU可以共享LLC缓存,将大幅度提升GPU性能。
在这个环形总线上,分布着多个Ring Stop,也就是俗称的“站台”。这个“站台”在每个CPU/LLC块上具有两个连接点。环形总线的存在,可以大大减少核心访问三级缓存的周期。在以往的产品中,多个核心共享一个三级缓存,需要访问的话必须先经过流水线发送请求,在进行优先级排序之后才能进行。新的环形总线将三级缓存分割成了若干部分,借助于每个站台,核心可以快速的访问LLC。
在至强E5中,还沿用了SandyBridge架构的256位指令集。这部分其实在单路至强E3中就已经谈过,相比原来的128位指令集来说,256位指令集在性能上更为出色。有关这部分的内容我们可以看看E3处理器中是如何介绍的。
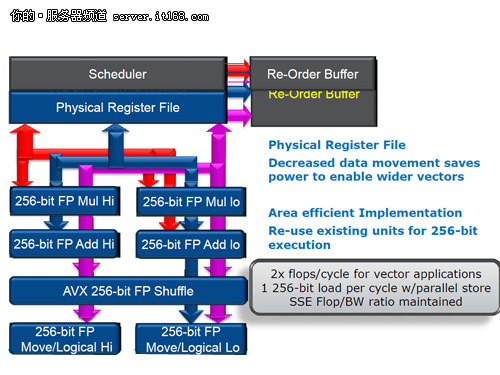
256bit指令集,让好事变得更好
Sandy Bridge的AVX将向量化宽度扩展到了256位,原有的16个128位XMM寄存器扩充为256位的YMM寄存 器,可以同时处理8个单精度浮点数和4个双精度浮点数。换句话说,Sandy Bridge的浮点吞吐能力可以达到前代的两倍。不过现在,AVX的256位向量还仅仅能够支持浮点运算。不过AVX的特别之处在于,它可以应用128位的SIMD整数和SIMD浮点路径。
AVX指令集是和Sandy Bridge微架构紧密结合的,因此,微架构的浮点寄存器也要从128位扩展到256位,此外,Load单元也要适应一次载入256位的能力,Sandy Bridge没有直接扩展原有Load单元的位宽,而是通过增加了一个Load单元来达到256bit Load的能力。
在进行新性能扩展的同时,AVX指令集的出现对于原有的X86指令集也进行了优化与重新组合——这主要源于AVX指令集新的操作码编码方式。AVX指令集的编码方式叫做VEX(Vector Extension),其主要用途是缩短指令长度,降低无谓的代码冗余,并且也降低了对解码器的压力,实现的方式也很特别——压缩各式各样的Prefix前缀,集中到一个比较固定的字段中,从而达到了精简指令集的目的。
刚刚我们在介绍E5-2600的时候,曾经提到过它的2个重大改进,就是双QPI通道和PCI-E 3.0支持。下面,我们就来详细介绍一下这两部分内容是怎么回事儿。
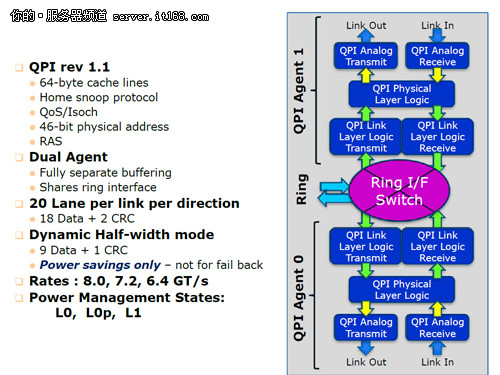
双QPI通道示意图
这里我们看到的是两个QPI管理模块。通过这两个模块,我们可以看到数据实现了同时互通,QPI具备了20条通道,同时可以动态分配10条通道。QPI通过环形总线与外界互通,达到了传输指令和数据的目的。
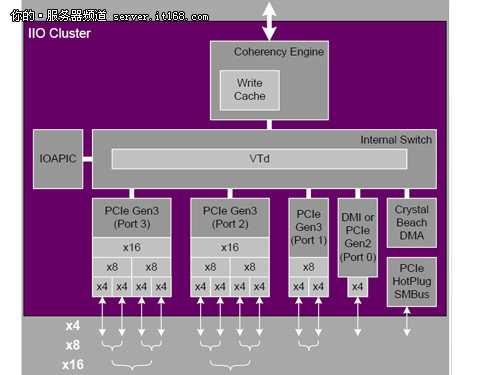
PCI-E 3.0示意图
我们可以看到,处理器的核外结构部分提供了PCI-E 3.0的功能,而相比上一代的PCI-E 2.0来说,它可以实现带宽数量的双倍提升,从4GT/s提升到8GT/s。更重要的是,这些通道之间可以随意组合,我们看到在PCI-E 3.0提供的40个通道中,每16个通道可以实现2个X8或者4个X4功能,这样对于有效分配带宽非常有帮助,因为并非所有的设备都需要X16通道才能支持。
由此看来,PCI-E 3.0提供了一种灵活的模式,大大增加了带宽的利用率。同时我们在这里也看到了PCI-E 2.0的身影,作为低速通道,它更大的作用的我实现一种补充,而且也只有X4一种规格。
刚刚我们介绍了许多处理器相关的内容,现在我们将视角转移到芯片组上来,看看SandyBridge的芯片组有哪些变化。这次至强E5-2600搭载的芯片组名称为C600。
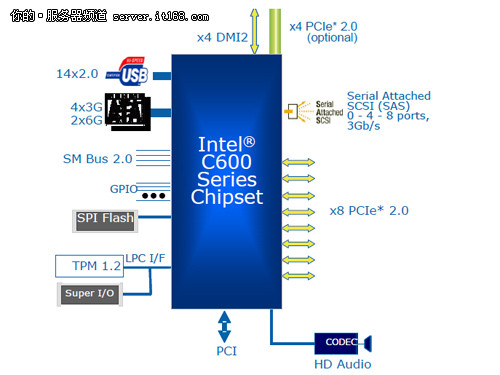
Intel C600芯片组示意图
我们来看看C600芯片组的支持设备图。首先我们发现,它通过PCI-E 2.0与处理器相连,这一点我们在刚才第3页的时候已经提到了。其次就是我们看到了PCI-E 2.0的字样,同样这也是作为PCI-E 3.0的补充而存在的。但究竟你所连接的设备是使用了PCI-E 3.0还是2.0,比如说你连接了一块SAS卡,这个只能依据主板型号的不同而判定了。
除了上面介绍的2内容之外,还有一个内容也是要注意的。在磁盘方面,C600芯片组提供了SATA接口下3Gbps和6Gbps两种磁盘的支持,但是板载的SAS接口却只能支持到最大8个3Gbps接口。如今许多SAS磁盘都是基于6Gbps接口的,也就是说用户需要使用额外的阵列卡才行。

Intel提供的官方主板设计图
从这个图上我们可以更好的落实刚刚说到的C600芯片组功能。值得一提的是这种双处理器并排的设计,这是Intel所一直强调的,因为这样才能保证在数据中心的环境中,两款处理器收到的散热效果相同。以往的前后设计做不到这一点,因此也被Intel全面的废弃了。
虽然没有提供SAS 6Gbps的支持,但是本次发布的E5-2600系列在磁盘方面也有独到之处。它有一个名为Data Direct I/O的特色技术(以下简称为DDIO),这项技术可以帮助处理器更快速、更智能的选择最短路线来读写数据,从而提升I/O性能。
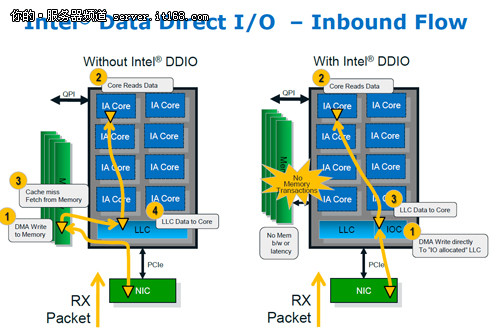
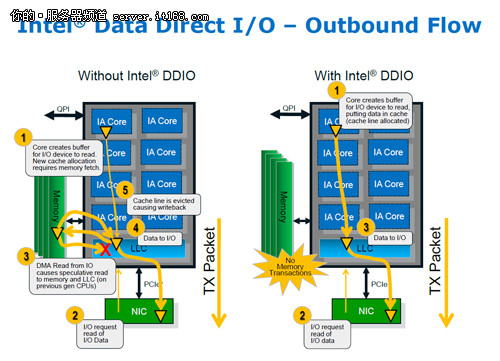
通过进出两个方向的对比,我们惊奇的发现如今数据的读写已经不需要像以前那样经过内存才能完成。从LLC可以直接传输到核心中,这样就节省了繁琐的操作步骤,提供了更短的相应时间。之前需要4-5步的操作如今可以简化到3步完成,流水线少了一环,自然也更加快捷。
如今节能是大家都在谈论的话题,而且数据中心应用的能耗是巨大的,因此在这一代的至强E5-2600系列中特别谈到了如何节能的问题。我们先来看看Intel自己有什么兼顾性能和节能的解决办法。
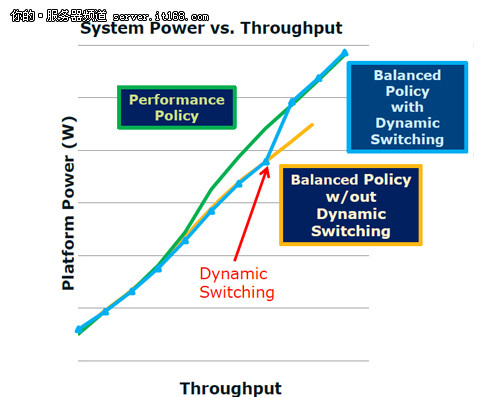
动态调整性能
在E5-2600系列中,英特尔提出了一个观点,就是如何使得兼顾性能的同时保证节能。这里有一个动态开关的概念。我们看到图中的3条线,绿色代表了最佳性能、蓝色代表了均衡性能(提供动态开关),而黄色代表了均衡性能(不提供动态开关)。
在开启了动态开关之后,我们会发现之前处于下风的均衡性能会有一个明显的提升,其吞吐量最终与最佳性能重合了。也就是说动态开关可以保证服务器即便在非最高性能运行的情况下,还可以实现高可用性,这在之前是没有的,也是一个新的突破。
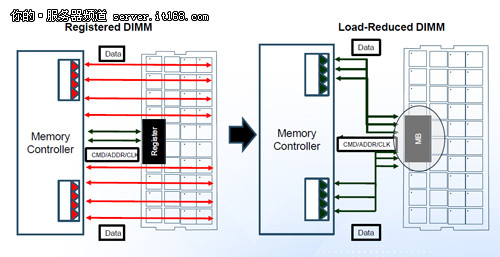
LR内存运行示意图
另外一个是又第三方内存厂商提供的。如今在强调虚拟化的同时,用户也在不断增加内存,这势必对服务器来说也是不小的能耗负担。LR内存的出现就是为了解决这一问题,它本身是低能耗的内存,而且相比传统的R-ECC内存来说我们可以明显的看到它通过一个缓存芯片实现了更快速的数据读写方式,这也是它性能提升的原因所在。

LR内存
提升了性能而又降低了功耗,这似乎是LR内存最大的作用。事实上,LR内存还可以实现非常大的存储容量,在双路平台中它可以实现最大384GB的容量,四路平台中这个数据将翻倍,达到768GB。
如今三星就已经推出了这种规格的内存,但是价位如何还是要等待市场的检验。
终于到了该揭晓一切内容的时候了。我们之前谈了那么多E5-2600的特征,无非都是纸上谈兵,毕竟大家没有亲眼看到这款处理器。现在我们就将介绍Intel送测的工程样机,它所搭载的正是目前高端的E5-2690处理器,我们一起来先睹为快吧。

Intel送测工程样机正面

Intel送测工程样机背面

Intel送测工程样机

前置接口
我们本次拿到的是Intel送测工程样机,因此在造型上与零售的服务器相比还有一定差距。这款机器是双路2U设计,使用了2.5英寸硬盘。但是我们测试的时候发现只有内置的一块SSD 710可以使用,因此前置的硬盘就没用到。
 机身内部设计
机身内部设计 

5个散热风扇
我们看到机身内部设计非常宽敞,也正是我们刚刚介绍的那款S2600GZ主板。它一共提供了24条DDR3内存插槽,包括了板载4个千兆网络接口和外接的2个万兆网络接口。
让我们激动不已的至强E5-2690处理器终于要登场了。


LGA2011接口

至强E5-2690处理器,主频为2.9GHz,工程样品
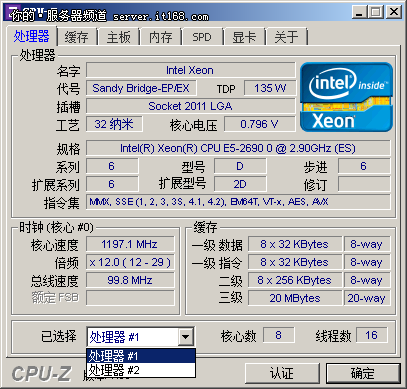
CPU-Z识别信息
我们使用了最新版的CPU-z 1.59来识别这款处理器,显示为至强E5-2690处理器,主频为2.9GHz,三级缓存为20MB,采用了32nm工艺,8核心16线程。TDP为135W,是E5系列处理器中最高的。


服务器所使用的是三星8GB DDR3 1600内存,共16根,总容量为128GB

测试平台使用的硬盘,SSD 710企业级产品,200GB容量


服务器使用的万兆网卡,来自Intel的82599芯片

服务器提供的电源,最大功率为750W,两块做了冗余
基本上,我们对于Intel送测工程样机的介绍就到这里了。下面我们将通过与上一代Westmere-EP处理器的对比,看看至强E5-2690处理器的优势在哪,也从侧面印证一下刚刚我们介绍的那些新功能是否有突破。
|
服务器平台信息
|
||
| 产品名称 |
至强E5-2690 |
至强X5680 |
| 平台类型 | Intel Sandy Bridge-EP | Intel 32nm Westmere-EP |
| 处理器子系统 | ||
|---|---|---|
| 处理器型号 | 至强E5-2690 | 至强X5680 |
| 处理器架构 | Intel 32nm Sandy Bridge-EP | Intel 32nm Westmere-EP |
| 代号 | Sandy Bridge-EP | Westmere-EP |
| 处理器封装 | Socket 2011 LGA | Socket 1366 LGA |
| 核心/线程数量 | 8/16 | 6/12 |
| 主频 | 2.9GHz | 2.4GHz |
| 处理器指令集 |
MMX,SSE,SSE2,SSE3, |
MMX,SSE,SSE2,SSE3, |
| 外部总线 |
DMI 8.0GT/S |
DMI 6.40GT/s |
| L1 Code Cache | 8× 32KB 8路集合关联 | 6x 32KB 8路集合关联 |
| L1 Data Cache | 8× 32KB 4路集合关联 | 6x 32KB 4路集合关联 |
| L2 Cache | 8× 256KB 8路集合关联 | 6x 256KB 8路集合关联 |
| L3 Cache | 20MB 20路集合关联 | 12MB 16路集合关联 |
| 服务器主板 | ||
| 型号主板 | Intel | ASUS Z8PS-D12-1U |
| 主板芯片组 | Intel C600 | Intel 5520 |
| 北桥芯片特性 | 2×QPI VT-d Gen 2 |
2×QPI VT-d Gen 2 |
| 子系统内存 | ||
| 控制器内存 | 每CPU集成三通道R-ECC DDR3 1600 | 每CPU集成三通道R-ECC DDR3 1333 |
| 内存类型 | 8GB LR-ECC DDR3 1600 SDRAM ×16条 | 4GB R-ECC DDR3 1333 SDRAM x6 |
| 软件环境 | ||
| 操作系统 | Microsoft Windows Server 2008 Enterprise R2 x64 | Microsoft Windows Server 2008 Enterprise R2 x64 |
从规格上我们可以看出几个变化。首先是至强E5-2690处理器的主频只有2.9GHz,而对比的产品X5680有3.3GHz,这会对测试成绩有一定影响,毕竟主频还是很关键的。其次就是在三级缓存方面,E5-2680的缓存为20MB,而上一代的X5680只有12MB,差距还是挺大的。其他两者都差不多,我们也选择了同样的软件系统,看看两者之间的性能差异。
对于性能方面的考察,我们主要分为子系统测试和应用性能测试。在子系统测试中我们按处理器、以及磁盘等各个子系统进行了分项测试,当然各子系统的测试成绩也是相辅相成,也需要其它子系统的支持,并非是完全独立的,只是对考察的子系统有所偏重而已。
处理器子系统测试
对服务器处理器子系统的考察,我们主要采用的是业界公认的SPEC 2006测试,该项测试通过对数十个典型应用程序的运行,来测试系统处理器子系统在应用中的整、浮点运算效率。SPEC 2006测试具有很好的开放性,因此在业界为广大用户所接受,可以利用这一公开的测试结果进行系统间运算性能的比较。CPUCPU
此外SiSoftware Sandra也有测试子项可用于处理器运算性能测试,其结果通常以每秒完成的指令数来表现。也可以用作不同处理器间运算效率的比较。
SPEC CPU 2006 v1.1
SPEC是标准性能评估公司(Standard Performance Evaluation Corporation)的简称。SPEC是由计算机厂商、系统集成商、大学、研究机构、咨询等多家公司组成的非营利性组织,这个组织的目标是建立、维护一套用于评估计算机系统的标准。
SPEC CPU 2006是SPEC组织推出的CPU子系统评估软件最新版,我们之前使用的是SPEC CPU 2000。和上一个版本一样,SPEC CPU 2006包括了CINT2006和CFP2006两个子项目,前者用于测量和对比整数性能,后者则用于测量和对比浮点性能,SPEC CPU 2006中对SPEC CPU 2000中的一些测试进行了升级,并抛弃/加入了一些测试,因此两个版本测试得分并没有可比较性。
SPEC CPU测试中,测试系统的处理器、子系统和使用到的编译器(SPEC CPU提供的是源代码,并且允许测试用户进行一定的编译优化)都会影响最终的测试性能,而I/O(磁盘)、网络、和图形子系统对于SPEC CPU2006的影响非常的小。操作系统内存
SPECfp测试过程中同时执行多个实例(instance),测量系统执行计算密集型浮点操作的能力,比如CAD/CAM、科学计算等方面应用可以参考这个结果。SPECint测试过程中同时执行多个实例(instances),然后测试系统同时执行多个计算密集型整数操作的能力,可以很好的反映诸如数据库服务器、电子邮件服务器和Web服务器等基于整数应用的多处理器系统的性能。
我们在被测服务器中安装了Intel C++ 11.1.034 Compiler、Intel Fortran 11.1.034 Compiler这两款SPEC CPU 2006必需的编译器,通过最新出现的QxS编译参数,Intel Compiler 10版本开始支持对Intel SSE4指令集进行优化(假如只支持SSE3,则使用QxT编译参数)。我们另外安装了Microsoft Visual Studio 2005 SP1提供必要的库文件。按照SPEC的要求我们根据自己的情况编辑了新的Config文件,使用了较多的编译选项。我们根据被测系统选择实际可同时处理的线程数量,最后得到SPEC rate base测试结果(基于base标准编译,SPEC base rate测试代表系统同时处理多个任务的能力)。
和其它测试部件不同,SPEC CPU 2006需要大量的系统物理内存,我们的SPEC测试在64位的Windows Server 2008 R2 下完成,对于每个运算核心,最低配置1.5GB内存。
内存子系统测试
对于内存子系统的考察,也是利用SiSoftware Sandra来实现,在该软件中有相应组件可进行内存带宽、内存延迟等方面的测试。
SiSoftware Sandra v2012
SiSoftware Sandra是一款可运行在32bit和64bit Windows上的分析软件,这款软件可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。从2007开始,Sandra的Arithmetic benchmarks增加了对SSE3&SSE4 SSE4的支持,在Multi-Media benchmark中增加了对于SSE4的支持,另外还升级了File System benchmark和Removable Storage benchmark两个子项目。对于新的硬件的支持当然也是该软件每次升级的重要内容之一,SiSoftware Sandra 2012对NUMA架构以及最新的Windows 7/Windows Server 2008 R2提供了更好的支持,此外测试项目和测试结果也有了略微的变化。SiSoftware Sandra所有的基准测试都针对SMP和SMT进行了优化,最高可支持32/64路平台。操作系统
之前在介绍处理器规格的时候,我们看到了部分CPU-z软件的截图,现在我们来一起了解一下软件给出的系统详细信息。
E5-2690处理器介绍,刚刚讲过了
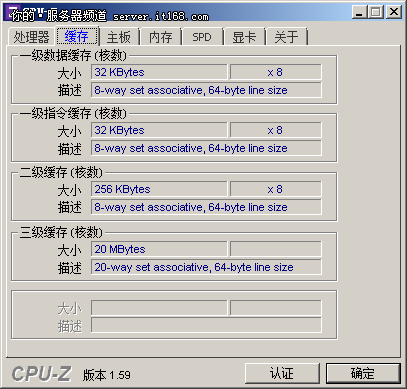
处理器缓存介绍,三级缓存增加到了20MB,上一代的Westmere是12MB
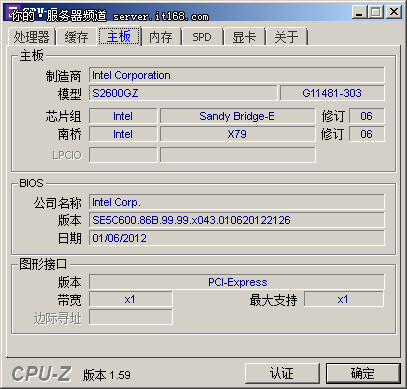 主板信息,显然软件还是有点问题,认出的是X79,这是消费类的主板型号(后面倒是有C600的字样)
主板信息,显然软件还是有点问题,认出的是X79,这是消费类的主板型号(后面倒是有C600的字样) 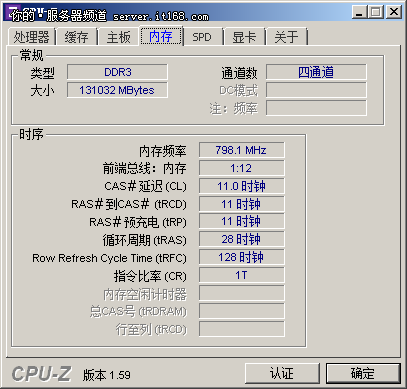
内存识别,这里可以看到系统的128GB内存,而且很明显的看到四通道的字样
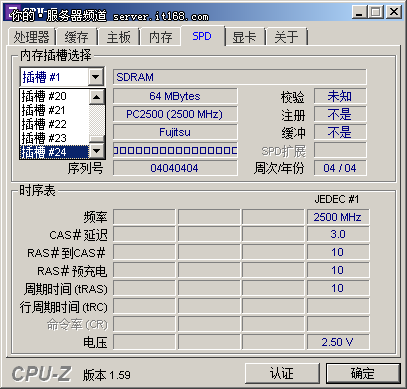
24条内存插槽
AIDA64是一款测试软硬件系统信息的工具,它可以详细的显示出PC的每一个方面的信息。AIDA64不仅提供了诸如协助超频,硬件侦错,压力测试和传感器监测等多种功能,而且还可以对处理器,系统内存和磁盘驱动器的性能进行全面评估。
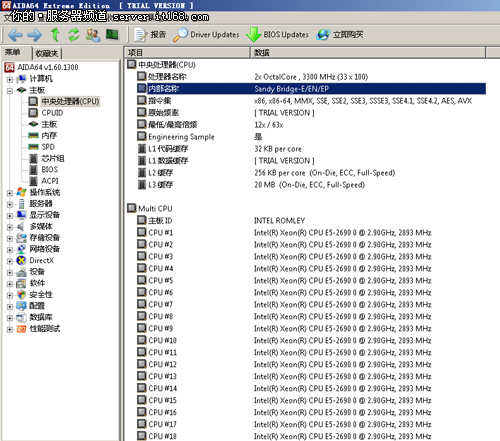
测试的显示器屏幕太小了,没有完整的32个处理器核心(包括超线程)图片
内存的识别也有些问题,比实际的小了点,软件误差,哎呀
SiSoftware Sandra软件我们常用的处理器计算性能测试软件。在至强E3新出现的时候,我们将这款软件升级到了2011版本。而如今,这款软件最新的版本是2012,也只有此版本可以更好的支持至强E5处理器。虽然是Lite版本,但是对于我们的测试来说并无大碍。
| SiSoftware Sandra Pro Business 2012 | ||||
| 产品名称 | Xeon E5-2690 | Xeon X5680 | ||
| 平台类型 | 双路Intel SandyBridge-EP | 双路Intel Westmere-EP | ||
| Processor Arithmetic Benchmark 处理器算术运算测试 |
||||
| 总计本地功效 | 408.69GOPS | 249.2GOPS | ||
| 总计本地功效对比速度 | 107.81MOPS/MHz | 74.75MOPS/MHz | ||
| Dhrystone iSSE4.2 | 520.5GIPS | 291.36GIPS | ||
| Dhrystone iSSE4.2 vs SPEED | 137.3MIPS/MHz | 87.39MIPS/MHz | ||
| Whetstone iSSE3 | 320.9GFLOPS | 207GFLOPS | ||
| Dhrystone iSSE3 vs SPEED | 84.65MFLOPS/MHz | 62.1MFLOPS/MHz | ||
| Processor Multi-Media Benchmark 处理器多媒体测试 |
||||
| 总计多媒体功效 | 651.27 MPixel/s | – | ||
| 总计多媒体功效对比速度 | 171.79kPixels/s/MHz | – | ||
| Multi-Media Int x16 iSSE4.1 | 746.66 MPixel/s | 534.13MPixel/s | ||
| Multi-Media Int x16 iSSE4.1 vs SPEED | 196.96 kPixel/s/MHz | 160.21kPixel/s/MHz | ||
| Multi-Media Float x8 iSSE2 | 568.07 MPixel/s | 397.47MPixel/s | ||
| Multi-Media Float x8 iSSE2 vs SPEED | 149.86kPixels/s/MHz | 119.22kPixels/s/MHz | ||
| Multi-Media Double x4 iSSE2 | 312.62 MPixel/s | 216.17MPixel/s | ||
| Multi-Media Double x4 iSSE2 vs SPEED | 82.47 kPixels/s/MHz | 64.84kPixels/s/MHz | ||
| Multi-Core Efficiency Benchmark 处理器效能测试 |
||||
| 内联核带宽 | 72.58 GB/s | 84GB/s | ||
| 内联核带宽对比速度 | 19.61 MB/s/MHz | 25.79MB/s/MHz | ||
| 内联核延迟(越小越好) | 117.1ns | 16ns | ||
| 内联核延迟对比速度(越小越好) | 0.31 ns/MHz | 0.00ns/MHz | ||
| .NET Arithmetic Benchmark .NET算术运算测试 |
||||
| 总计 .NET 功效 | 69.42 GOPS | – | ||
| 总计 .NET 功效对比速度 | 18.31 MOPS/MHz | – | ||
| Dhrystone .NET | 27.84 GIPS | 37GIPS | ||
| Dhrystone .NET vs SPEED | 7.34 MIPS/MHz | 24.06MIPS/MHz | ||
| Whetstone .NET | 173.1 GFLOPS | 123.43GFLOPS | ||
| Whetstone .NET vs SPEED | 45.66 MFLOPS/MHz | 37.02MFLOPS/MHz | ||
| .NET Multi-Media Benchmark .NET多媒体测试 |
||||
| 总计多媒体.NET功效 | 114 MPixel/s | – | ||
| 总计多媒体.NET功效对比速度 | 31.74 kPixels/s/MHz | – | ||
| 多媒体整数 x1 .NET | 126.14 MPixel/s | 100.36MPixel/s | ||
| 多媒体整数x1 .NET vs SPEED | 35.13 kPixels/s/MHz | 30.10kPixels/s/MHz | ||
| 多媒体浮点数 x1 .NET | 51.47 MPixel/s | 42.42MPixel/s | ||
| 多媒体浮点数 x1 .NET vs SPEED | 14.33 kPixels/s/MHz | 12.72kPixels/s/MHz | ||
| 多媒体双精度 x1 .NET | 103 MPixel/s | 78.48MPixel/s | ||
| 多媒体双精度 x1 .NET vs SPEED | 28.67 kPixels/s/MHz | 23.54kPixels/s/MHz | ||
结果真是让人大吃一惊。在运算性能上E5-2690以压倒式的优势取得领先,成绩甚至是上一代产品的一倍以上。当然这仅仅是指计算性能,在多媒体方面,成绩则病没有那么夸张,但是据大多数项目都有40%以上的优势,这个成绩是我们必须肯定的,也就是说新架构的确带来了不同的效果。
看过了计算性能,我们再来看内存与缓存的性能。内存方面我们知道,除了处理器内部的改进之外,就是内存升级到了4通道,支持DDR3 1600;缓存方面就是从8MB提升到了20MB。这些提升有多大的变化?看看就知道了。
| Memory Bandwidth Benchmark 内存带宽测试 |
||
| 总体内存性能 | 34.31GB/s | - |
| 总体内存性能对比速度 | 21.96MB/sMHz | - |
| 整数 B/F iSSE2 内存带宽 | 31.54GB/s | 35.2GB/s |
| 整数 B/F iSSE2 内存带宽对比速度 | 20.19MB/sMHz | - |
| 浮点数 B/F iSSE2 内存带宽 | 37.33GB/s | 35.18GB/s |
| 浮点数 B/F iSSE2 内存带宽对比速度 | 23.89MB/sMHz | - |
| Memory Latency Benchmark 内存延迟测试 |
||
| 内存延迟(越小越好) | 87.8ns | 82ns |
| 内存延迟对比速度 (越小越好) | 0.05s/MHz | - |
| 速度因素 (越小越好) | 81.90 | 64.60 |
| 内部数据高速缓存 | 3.1clocks | 4clocks |
| 二级板载高速缓存 | 9.3clocks | 10clocks |
| 三级板载高速缓存 | 41.5clocks | 60clocks |
| Cache and Memory Benchmark 缓存及内存测试 |
||
| 缓存/内存带宽 | 509.48 GB/s | 195.6GB/s |
| 缓存/内存带宽对比速度 | 137.62MB/s/MHz | 60.07MB/s/MHz |
| 速度因素(越小越好) | 30.90 | 35.20 |
| 内部数据高速缓存 | 1.51TB/s | 744.49GB/s |
| 二级板载高速缓存 | 1TB/s | 611GB/s |
| 三级板载高速缓存 | 517.84GB/s | - |
内存部分总体看起来与上一代的差别不大,只是借助于缓存的优势的确能够降低一些延迟,另外缓存的测试成绩也有了近一倍的提升。
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、内存子系统以及显示子系统,我们的平台偏向于服务器多一些,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。
值得一提的是,原来的CineBench R10已经不能再适应如今的测试需要,因为R10只能支持24个处理器核心。如今的核心数量为32个(算上超线程),所以只有R11.5能够支持最多48个核心。
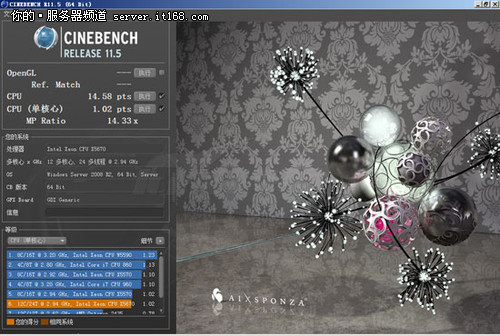
Westmere-EP测试成绩
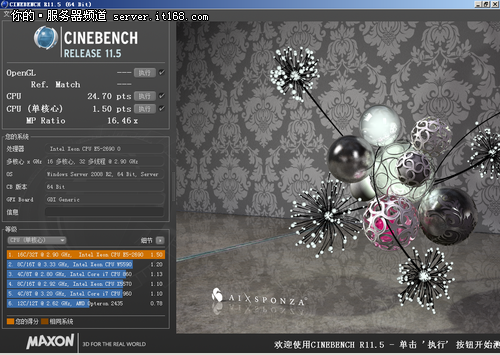
SandyBridge-EP测试成绩
测试成绩不可同日而语。在至强X5680中,单核心成绩只有1.02,这次提升到了1.50;多核心成绩为14.58,这次提升到了24.70。不过MP成绩没有太多的变化,这是又架构来决定的。总体说来,提升幅度在50%以上,性能很可观。
SPEC是标准性能评估公司(Standard Performance Evaluation Corporation)的简称。SPEC是由计算机厂商、系统集成商、大学、研究机构、咨询等多家公司组成的非营利性组织,这个组织的目标是建立、维护一套用于评估计算机系统的标准。
SPEC 2006是SPEC组织推出的一套子系统评估软件,它包括CINT2006和CFP2006两个子项目,前者用于测量和对比整数性能,而后者则用于测量和对比浮点性能。计算系统中的处理器、和编译器都会影响最终的测试性能,而I/O(磁盘)、网络、和图形子系统对于SPEC CPU2006的影响比较小。操作系统内存CPUCPU
SPECfp测试过程中同时执行多个实例(instance),测量系统执行计算密集型浮点操作的能力,比如CAD/CAM、DCC以及科学计算等方面应用可以参考这个结果。SPECint测试过程中同时执行多个实例(instances),然后测试系统同时执行多个计算密集型整数操作的能力,可以很好的反映诸如数据库、电子邮件和Web服务器等基于整数应用的多处理器系统的性能。服务器服务器
为了运行SPEC CPU 2006测试,我们统一安装了Windows Server 2008 Enterprise x64 Edition SP1,在主流的x64处理器下,原生64应用要比32位下快。我们还安装了Visual Studio 2005 SP1、 C++/Fortran Compiler 10.0.025编译器,对于支持SSE3指令集的处理器,我们使用了QxO编译指令进行了优化。编译时未使用SmartHeap商业优化库。Intel操作系统
SPEC测试代表了绝大多CPU密集型的运算,包括编程语言、压缩、人工智能、基因序列搜索、视频压缩及各种力学的计算等,包含了多种科学计算,可以用来衡量系统执行这些任务的快慢。SPEC base测试包括浮点(fp)与整数运算(int)两部分。
整数运算主要包含编译、压缩、人工智能、视频压缩转换、XML处理等,此外,各种日常操作也主要是基于整数操作。SPEC CPU 2006的整数运算包含了400.perlbench PERL编程语言、401.bzip2 压缩、403.gcc C编译器、429.mcf 组合优化、445.gobmk 人工智能:围棋、456.hmmer 基因序列搜索、458.sjeng 人工智能:国际象棋、462.libquantum 物理:计算、464.h264ref 视频压缩、471.omnetpp 离散事件仿真、473.astar 寻路算法、483.xalancbmk XML处理共12项。量子
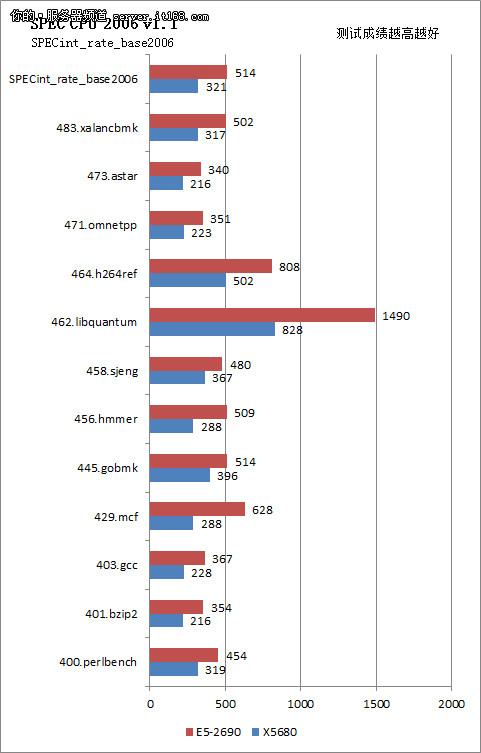
SPEC CPU 2006整数测试成绩
浮点运算包括的全部都是科学运算,科学运算需要用到大量的高精度浮点数据,如410.bwaves 流体力学、416.gamess 化学、433.milc 量子力学、434.zeusmp 物理:计算流体力学、435.gromacs 生物化学/分子力学、436.cactusADM 物理:广义相对论、437.leslie3d 流体力学、444.namd 生物/分子、447.dealII 有限元分析、450.soplex 线形编程、优化、453.povray 影像光线追踪、454.calculix 结构力学、459.GemsFDTD 计算电磁学、465.tonto 量子化学、470.lbm 流体力学、481.wrf 天气预报、482.sphinx3 语音识别共17项测试。量子
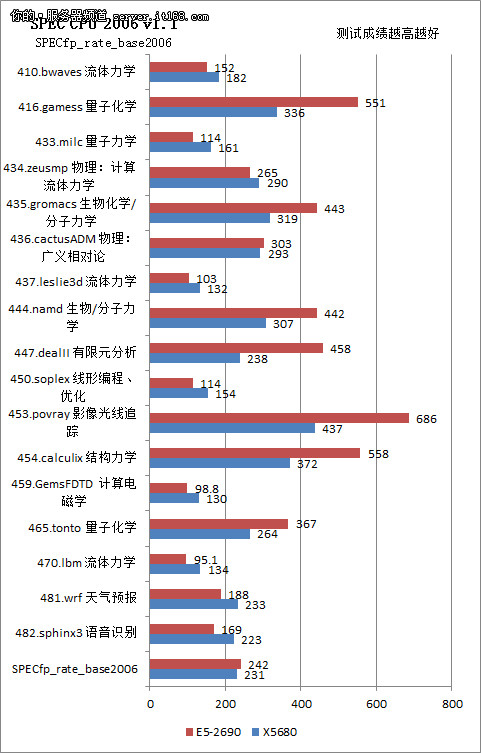
SPEC CPU 2006浮点运算测试成绩
首先说明一个问题,就是我们对比所使用的至强X5680处理器是一款主频在3.33GHz的产品,而对比的E5-2690主频只有2.9GHz。我们知道,在SPEC CPU测试中,主频会起到很大的作用,因此有必要说明一下。
即便主频占优,但是我们看到在整数运算中X5680全面落败,多数项目落后在60%以上,部分项目只有E5-2690的30-40%。这也从侧面说明了E5-2690在架构上的先进性,即便不依靠主频还是可以取胜。浮点运算的成绩中,X5680凭借主频取得了部分项目的领先优势,但是整体还是不敌E5-2690,差距还是很明显的。
我们利用Aitek AWE2101数字功率计和配套的软件测试了整个服务器平台在几种不同的状态下的功耗,AWE2101是一个高精度的数字功耗测试仪,主要包括如下项目:
P1:连接但不开机状态电源
P2:系统启动完毕,5分钟内无动作,但不休眠
P3:系统启动完毕,处理器满载、磁盘以最大吞吐量工作

5位数字精度
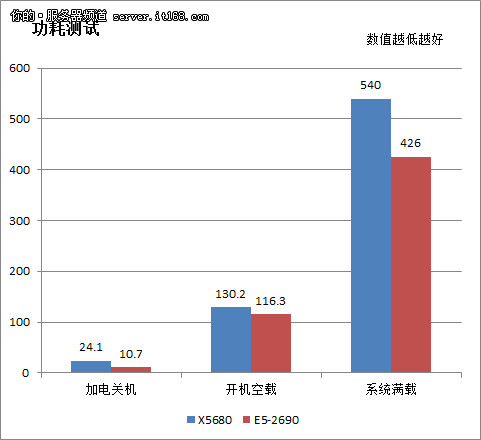
在图上我们终于看到了至强X5680的领先状态,只是这种领先并非是好事情,这里的成绩应该是越低越好。同时需要说明的是,至强X5680的TDP为130W,而E5-2690的TDP为135W,还要高出一点点。但是实际测试的成绩,在空载方面两者差不多,但是峰值功率有了非常明显的差距。测试显示,至强E5-2690平台相比上一代要节约最大20%以上的能耗,这个数字非常惊人。
测试到了这里,也就接近尾声了。对于英特尔这款刚刚推出的E5-2600系列处理器来说,这个测试仅仅是一个开始,未来我们将会看到来自各个服务器厂商的产品,到那时我们将更为深入的了解到E5-2600的点点滴滴。

从更新换代的角度来说,E5-2600无疑是一款成功的服务器。在进行了架构革新之后,它的身上已经完全看不到Westmere的影子,取而代之的是全新的SandyBridge系列。而相比小兄弟E3处理器来说,至强E5更重要的是在双路互联上发生了变化,这种变化为处理器提供了新的动力。当然,核心数量的增加也是必须的,它也是衡量处理器能力的一个重要硬件指标。
从对比上我们可以看出,至强E5-2690相比上一代的X5680来说在性能上有了明显的进步,这些进步带来的提升是巨大的,部分项目翻了几番,普通的项目也有60%以上的提升。对于应用来说,更快速的相应时间、更强大的动力性能和更低的功耗则是我们希望看到的,英特尔的确给了我们这些新的惊喜。
至强E5,他来了,这或许是英特尔2012年为我们提供的最好的一份礼物。如果将英特尔比作一个大人,将新推出的E5-2690比作婴儿的话,我就会说——仅以此文,献给那刚刚出生的孩子,祝你健康成长。







