
自动存储分层和NetApp 虚拟存储层
Paul Feresten&Rajesh Sundaram 发表于:11年06月03日 11:42 [来稿] DOIT.com.cn
以下几个因素会影响 AST 解决方案实现上述目标的能力:
·数据存储的粒度如何?处理的数据块越小,用于存储数据的系统和 HDD 资源的效率就越高,并且冷数据“跟随”热数据移动并毫无益处地耗用昂贵介质的可能性也越小。
·如何识别热数据以及速度加快了多少?热数据进入闪存的速度越快,错过 I/O 活动中相对短暂的高峰期的可能性就越小,需要的 HDD I/O 就越少,并且平均延迟时间缩短的幅度就越大。
从操作角度来看,还需要考虑以下几个因素:
部署和管理该解决方案的难度如何?如果部署 AST 解决方案需要进行重大的重新配置,或需要大量的监控和管理,那么可能会得不偿失。
该解决方案如何与您使用的其他存储技术(备份、重复数据删除、精简配置等)集成?您一定不希望在部署一个解决方案之后,发现备份不能执行,或者虽然能执行,但却需要大量地移动数据。
实现 AST 的两种不同方式:迁移与缓存
实现 AST 有两种本质上不同的方式:迁移和缓存。
基于迁移的 AST 可自动化数据迁移的流程。当一个数据块被确定为“热”数据时,会将该数据块移至速度较快的介质,当该数据块变“冷”时,会将其移回速度较慢的介质。移入和移出闪存都需要访问 HDD。
基于缓存的 AST 使用广为人知的缓存方式将热数据“提升”到高性能的介质中。由于 HDD 上仍保留有数据的副本,因此当数据变“冷”时,只需将其从缓存中释放即可,而不需要额外的 HDD I/O。
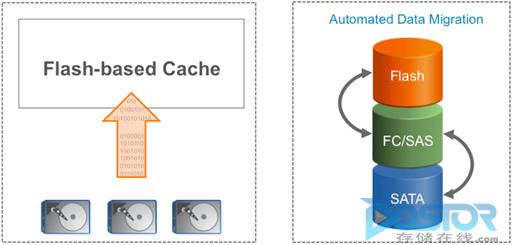
图 3) 基于缓存的自动存储分层与基于迁移的自动存储分层。
NetApp 虚拟存储层
根据我们前面讨论的评价标准,NetApp 考察了这两种实现 AST 的方式,并得出以下结论:基于缓存的 AST 方式更符合这些标准的要求。




