
2013年迄今为止最严重的云计算中断事故
看引擎 发表于:13年07月23日 11:00 [转载] DOIT.com.cn
Google Drive
日期:2013年3月18-19日,时间:约17小时;在3月18日星期一,很多用户在试图访问其Drive文档和文件时,出现加载缓慢或者超时的情况,这大约持续了约三小时。一天后,第二次Google Drive中断让一些用户在约两小时内无法访问该服务。这两天后,Drive再次停机12小时,这真的让用户非常恼火。
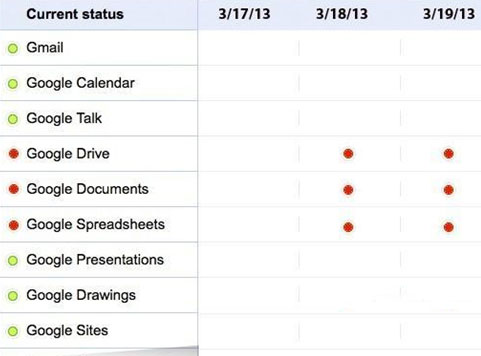
Google Drive事故影响
可以想象,论坛和社交网站又是各种抱怨。谷歌称最初的问题与该公司的网络控制软件中的故障有关。该系统显然没有负载均衡,导致该公司的服务器出现不必要的延迟。而这反过来又导致Drive的连接管理系统出现问题。谷歌承诺将修复这个漏洞,调整其负载均衡设置,确保其网络服务之间“更大的隔离度”。该公司还调整了其Drive软件来让该服务在面对延迟和恢复时“更具弹性”。

CloudFare网站崩溃
日期:2013年3月3日;持续时间:大约一个小时;CloudFare的业务主要围绕帮助客户保护和加速网站,但在3月3日早上,该公司自己的网站以及所有的服务都出现故障,导致785000个其他网站崩溃,包括Wikileaks、4chan以及一些政府网站。

CloudFare事故影响
在大约一小时内,当你试图访问任何CloudFare连接的网站时,你都会得到一个“无法路由到主机”的错误信息。CloudFare公司声称边缘路由器(连接CloudFare的系统到互联网)的系统故障是这次事故的主要原因。虽然几台路由器的崩溃通常会导致流量转移,但在这种情况下,一个漏洞能让每台路由器脱机。工程师发现了有问题的代码,清除掉了代码,然后需要等待14个不同国家的23个数据中心重新启动所有路由器。

Dropbox再次出现故障
日期:2013年5月30日;时间:约90分钟;在五个月正常运转之后,Dropbox在5月底又出现了故障。这次,该服务中断约90分钟,让客户无法访问其文件或者上传任何新的材料。

Dropbox事故影响
在经历1月份16小时的宕机事故后,人们似乎有点能够接受该服务再次宕机的事实。幸运的是,这次事故并没有持续太长时间。面对2013年第二次故障,Dropbox比上次更加沉着,只是表示其服务已经恢复正常,并对易造成的任何不便,表示道歉。

Twitter服务中断
日期:2013年6月3日;时间:约45分钟6月3日,Twiter用户无法访问该服务来发送或读取内容。在大约25分钟后,服务有所恢复,但仍然很缓慢。

Twitter事故影响
在Twitter无法使用的时段时间,Google+可能出现了高峰,所有的人都在询问其他人Twitter是否可用。Twitter表示在发送Fail Whale到该网站的“日常更改”中出现了一个错误。工程师在确定这个问题后,取消了这个错误的更改,服务很快就恢复了正常。(邹铮编译)感谢观看!希望中断事故越来越少。




