
西瓜哥 发表于:13年08月27日 14:24 [原创] DOIT.com.cn
通过上述大家应该基本掌握了RAID 2.0的原理。今天我们就来聊聊RAID 2.0的可靠性问题。
可靠性是一个非常复杂的问题,我不是这方面的专家,我只是从我收集的资料整理一下分享给大家。
可靠性和性能也经常是矛盾的,作为用户,有时需要平衡,这个是一个艺术问题,哈,你别不信,看完我今天的分析,估计你也有同感。
我们先从理论上分析一下RAID 2.0的可靠性。
大家知道,系统的可靠性=MTBF / ( MTBF + MTTR ) * 100%
RAID 2.0(3PAR叫FAST RAID),通过把数据分散到更多的磁盘,重构时间缩短,MTTR应该大大缩小了。但有一个问题,就是针对某一个LUN来说,由于数据分散到更多的盘,因此数据丢失的风险大大提高,即MTBF变大了。比如我采用传统的RAID 5(3+1),4个盘同时坏两个的概率是很小的,但如果用RAID 2.0, 假设这些数据分散到100个盘上,100个盘同时坏2个盘的概率大多了。虽然重构速度很快,但双盘失效的概率也提高了。那么到底重构减低的风险是否能够平衡掉双盘失效带来的风险呢?(什么,你一直想问这个问题,说明你入道了,很多童鞋是问不出这个问题来的。对RAID不了解的可以找度娘补习一下。老实说,我刚学习RAID 2.0的时候第一个问题就是这个,问了很多人,今天还未能完全解决)。
Markov模型是经典的可靠性预计模型,采用Markov模型可以根据系统当前状态及转移条件,来预计系统的可靠性指标。
马尔科夫是俄罗斯著名的数学家,计算公式复杂(我很佩服数学家,这么复杂的计算怎么算出来的),我想大家和我一样都是俗人,不会自己去算了,对吧。好,我从非官方渠道拿到一份可靠性技术的白皮书,在这里第一时间分享给大家计算结果:
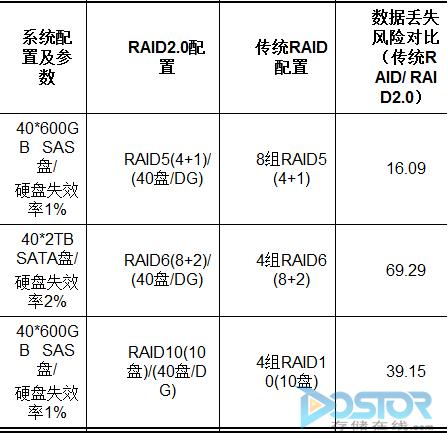
我来解读一下这个结果。这个结果说明,从理论上来说,RAID 2.0系统比RAID 1.0系统丢失数据的风险要小很多。但是别急,这个是对整个系统来说的。也就是说,针对这个高端阵列的管理员,他觉得不错,整个系统的可靠性提高了。但针对这个高端阵列的某个最终用户(比如ERP系统这个应用的IT人员帅锅小L)来说,好像不是这么回事。小L只关心ERP的数据,原来采用RAID 1.0,数据存放在5块盘上,同时坏两块盘的概率比地震都小,现在你把小L的数据均衡分布到100块盘上了,小L他晚上能睡着吗?
我也在寻求这个答案,谷歌和度娘都找不到答案。有可靠性专家和我说,其实,这种情况下RAID 2.0的可靠性并不比RAID 1.0有优势,对于传统RAID和RAID2.0,发生数据丢失的概率和丢失的数据量均近似有“随着系统盘数和硬盘容量的增加而成比例增大”(因此,性能够用就好,西瓜池也不要搞太大了)。虽然出现故障丢失的数据量要比RAID 1.0少,这对文件系统和归档来说问题不大,但对于数据库来说,丢一点都不行。因此,重构速度虽然快了,半小时搞定,但万一半小时内再坏第二块盘怎么办?用RAID 10或者RAID 6,或者做容灾。对头,可靠性要匹配你的需求,这个世界上没有完全可靠的东西,包括爱情,哈。
注意:上面的分析没有考虑RAID 1.0重构负载重可能导致的加快硬盘过劳死的风险,因为这个没法算。
RAID 10和RAID 6哪个更可靠?
大家知道,RAID 6最多可以坏任意两块盘数据不丢失,RAID 10可能坏一半的盘数据也可能不会丢失。那个的可靠性高?我估计80%以上的人认为是RAID 10可靠,如果你也是这么认为的,请马上回复微信告诉我,我看看我的判断对不对。其实我也和你们一样,我一直认为RAID 10更可靠,直到某天一个可靠性专家给我一份材料,IBM的红皮书,圣经啊。在IBM的一本DS5000的红皮书里,IBM经过计算,结论就是RAID 6的可靠性最高,其次才是RAID 10,最差是RAID 5。
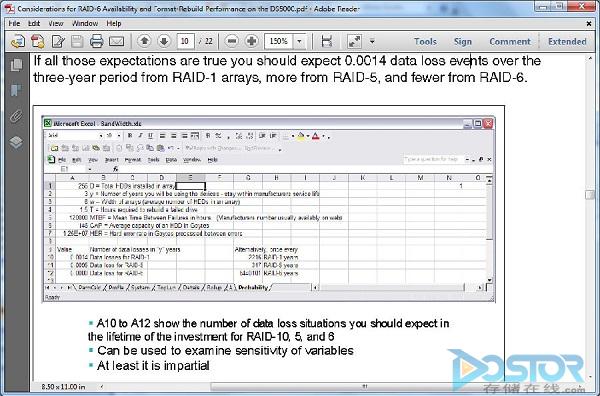
但你知道为什么现在无数的数据库都推荐用RAID 10了吗?因为性能。RAID 10的读写性能好很多。我说性能和可靠性的平衡是一个艺术,这回你相信了吧?
网上一直有传说说IBM XIV容易丢数据,我一直不信,现在想想,信了。为什么呢?它全部用SATA盘(现在它也叫SAS盘,其实是假的,是NL-SAS,也就是SAS接口,SATA的盘体),采用伪随机算法把数据以1M大小的CHUNK平均分布到所有的磁盘上。SATA盘的可靠性本来就比较差,你分布到180块盘,就算你重构速度块,同时坏2块盘必然会造成数据丢失(因为肯定有某1个CHUNK就在这两块盘上)。
对于RAID 2.0来说,已经好多了,RAID可以选择RAID 6。对于传统的高端阵列厂商IBM DS8000/EMC/HDS,他们由于历史原因,底层代码不能变,还是用传统的RAID,但为了实现自动分层和性能不变,必须要直接切第二刀Extend,对不对? 但在这种RAID 1.5的改良对可靠性更加是个噩梦,我们来欣赏一下IBM DS8000的红皮书里面的描述:
看到没有,由于DS8000的第二到必须在存储池里面切,而这个存储池底层是由多个传统的RAID组(RANK)组成,因此,如果一个RAID组失效,一个池的数据都丢失了。因此,你害怕丢失,请容灾。为了控制这个,我记得DS8000一个pool下最多放4个RAID组,而HDS直接建议用RAID 6。你看看,RAID 1.5限制是否很多,RAID 2.0真正从底层解决这些问题就好多了。再一次说明,可靠性和性能功能的平衡,真是一个艺术活。
最后,我们再谈一下重构时间。
先说一下我收集到的各个厂商宣传的数据:
HW:1TB重构时间30分钟,比传统RAID需要10个小时快20倍;
IBM XIV:1TB重构时间30分钟;
3PAR:在老的胶片上写的是重构速度快2倍;
我喜欢刨根问底,我们来分析一下:大家知道,7200RPM的SATA盘写的带宽大约115MB/s,因此,如果采用RAID 1.0,理论上需要2.5小时写1TB的数据。因为重构的时候只能写一个热备盘,这是瓶颈。但一般的系统都是有负载的,重构的优先级一般都是最低的,因为用户要保证业务的运行,因此,一般的重构时间基本都是理论时间的2-5倍。因此,如果RAID 2.0参与的盘很多,那个30分钟是可以达到的。而如果传统的RAID 1.0有较高的负载,重构需要10个小时也是正常的。因此,HW的宣传虽然稍微有点夸大,但基本属实。最关键就是RAID 2.0重构的时候对业务基本没有影响,因为没有热点盘。而RAID 1.0重构,对业务的影响是巨大的,反过来也影响到重构的速度。
为了验证我的想法,我再从互联网上找一下3PAR的用户发布的重构数据。
https://storagemojo.com/2010/02/27/does-raid-6-stops-working-in-2019/
这个用户分享了采用3PAR的fast RAID,SATA盘重构时间只化了4分钟(这个发挥了RAID 2.0的最大好处,只重构用过的CHUNK,而不用整盘重构,估计数据量比较小),而原来采用老的阵列,重构时间是24小时(SATA盘)和4-6小时(FC盘)。我也看到另外一个用户说说他采用3PAR的阵列,重构750GB的数据用了3个小时(业务负载特别重),不过对业务性能没有任何影响(怪不到3PAR宣称它是唯一一个可以在业务期间换盘的高端存储厂商,不过现在HW HVS把它的唯一去掉了,呵呵)。这说明重构时间也是一个艺术活,和数据量和业务负载,硬件特性等等都有关系。
最后分享一个我想了很长时间才想明白的事情,为什么RAID 2.0的重构的总数据量少?RAID 1.0也不是全盘重构的啊?(我估计你们肯定也想不明白)。后来在我上周苦练切西瓜刀法后恍然大悟,RAID 1.0能够感知的是LUN,也就是说,从一个RAID组里划分出LUN后,虽然主机还没有写任何东西,但是系统不知道,因此重构的时候都重构了,一般阵列初始化的时候,肯定把LUN都划了,因此相当于整盘重构了。但RAID 2.0划分为CHUNK,每个CHUNK上都有标签,没有分配的CHUNK,或者分配了没有被写过的CHUNK系统都清楚,当然只会重构有数据的CHUNK了,而不是整个LUN。
最后问大家一个问题,采用哪种RAID级别,RAID 2.0相比RAID 1.0重构时间提升最大?哈哈,RAID 10。假设不考虑做奇偶校验的时间,所有的RAID 1.0的重构时间是一样的,因为只能同时写1块热备盘,瓶颈在热备盘上。但采用RAID 2.0后,瓶颈不在写盘上了,RAID 5和RAID 6多了很多读数据的动作,而RAID 10就不用了,因此重构的速度提升是最明显的。
通过这些分析,大家估计得出的结论和我一样,RAID 2.0确实是一个颠覆性的技术,优点很多,而且有出色的性能和不逊于传统RAID的可靠性(带来业务的灵活性我们后面还会谈到),并且业界采用了十几年(3PAR 1999年就用了),应该是一个经过市场检验的RAID方法,应该也是高端存储以后的发展方向。
希望大家积极反馈你的意见和建议,微信扫描如下二维码,关注微信公众号“高端存储知识”,与作者微信互动。





